Lecture 03: Simple, Marginal, and Interaction Effects
More about general linear model
Jihong Zhang*, Ph.D
Educational Statistics and Research Methods (ESRM) Program*
University of Arkansas
2024-09-09
Presentation Outline
Homework 1 has been posted online
Centering and Coding Predictors
Interpreting Parameters in the Model for the Means
Main Effects Within Interactions
GLM Example 1: “Regression” vs. “ANOVA”
Today’s Plan
Unit 1: Review dummy coding and centering + A short In-Class quiz
Unit 2: Illustrate the GLM with interaction using on example
Unit 3: Practice R code + Q&A
Unit 1: Dummy Coding and Centering
Today’s Example:
Study examining effect of new instruction method (New: 0=Old, 1=New) on test performance (Test: % correct) in college freshmen vs. senior (Senior: 0=Freshman, 1=Senior). “New by Senior” leads to 4 groups with n = 25 per group (Group: 1= Ctl, 2=T1, 3=T2, 4=T4).
Note that Equation 1 (single group variable model) and Equation 2 (group interaction model) are equivalent models with exactly same sets of parameters.
Each person’s expected (predicted) outcome is a function of his/her values on x and z (and their interaction), each measured once person
Estimated parameters are called fixed effects (here, \(\beta_0\), \(\beta_1\), \(\beta_2\), and \(\beta_3\)); although they have a sampling distribution, they are not random variables
The number of fixed effects will show up in formulas as k (so k = 4 here)
Model for the Variance
\(e_p \sim N(0, \sigma^2_e) \rightarrow\) ONE residual (unexplained) deviation
\(e_p\) has a mean of 0 with some estimated constant variance \(\sigma^2_e\), is normally distributed, is unrelated across people
Estimated parameter is the residual variance only (in the model above)
General Form of Two Models
Model for the Means (Predicted Values): The Best Guess of Estimates
Variance-Covariance Matrix of Regression Coefficients (Diagnoal: variances of betas (squared standard errors of betas); Nondiagnoal: residual covariances between betas)
From now on, we will think carefully about how the predictor variables enter into the model for the means rather than the scales of predictors
Why don’t people always care about the scale of predictors (centering):
Does NOT affect the amount of outcome variance account for (\(R^2\))
Does NOT affect the outcomes values predicted by the model for the means (so long as the same predictor fixed effects are included)
Why should this matter to us?
Because the Intercept = expected outcome value when X = 0
Can end up with nonsense values for intercept if X = isn’t in the data
We will almost always need to deliberately adjust the scale of the predictor variables so that they have 0 values that could be observed in our data
Is much bigger deal in models with random effects (MLM) or GLM once interactions are included
Adjusting the Scale of Predictor Variables
For continuous (quantitative) predictors, we will make the intercept interpretable by centering:
Centering = subtract as constant from each person’s variable value so that the 0 value falls within the range of the new centered predictor variable
Typical \(\rightarrow\) Center around predictor’s mean: \(X_1^\prime = X_1 - \bar{X_1}\)
Better \(\rightarrow\) Center around meaningful constant C: \(X_1^\prime = X_1 - C\)
x <-rnorm(100, mean =1, sd =1)x_c <- x -mean(x)mean(x)mean(x_c)
[1] 1.019229
[1] 2.664535e-17
For categorical (grouping) predictors, either we or the program will make the intercept interpretable by creating a reference group:
Reference group is given a 0 value on all predictor variable created from the original group variable, such that the intercept is the expected outcome for that reference group specifically
Accomplished via “dummy coding” or “reference group coding”
For categorical predictors with more than two groups
We need to dummy coded the group variable using factor() in R
For example, I dummy coded group variable with group 1 as the reference
d1 = GroupT1 (0, 1, 0, 0) \(\rightarrow\)\(\beta_1\) = mean difference between Treatment1 vs. Control
d2 = GroupT2 (0, 0, 1, 0) \(\rightarrow\)\(\beta_2\) = mean difference between Treatment2 vs. Control
d3 = GroupT3 (0, 0, 0, 1) \(\rightarrow\)\(\beta_3\) = mean difference between Treatment3 vs. Control
How does the model give us all possible group difference?
Control Mean
Treatment 1 Mean
Treatment 2 Mean
Treatment 3 Mean
\(\beta_0\)
\(\beta_0+\beta_1\)
\(\beta_0+\beta_2\)
\(\beta_0+\beta_3\)
The model (coefficients with dummy coding) directly provides 3 differences (control vs. each treatment), and indirectly provides another 3 differences (differences between treatments)
Group differences from Dummy Codes
Set \(J = 4\) as number of groups:
The total number of group differences is \(J * (J-1) / 2 = 4*3/2 = 6\)
Control Mean
Treatment 1 Mean
Treatment 2 Mean
Treatment 3 Mean
\(\beta_0\)
\(\beta_0+\beta_1\)
\(\beta_0+\beta_2\)
\(\beta_0+\beta_3\)
All group differences
Alt Group
Ref Group
Difference
Control vs. T1
\((\beta_0+\beta_1)\)
- \(\beta_0\)
= \(\beta_1\)
Control vs. T2
\((\beta_0+\beta_2)\)
- \(\beta_0\)
= \(\beta_2\)
Control vs. T3
\((\beta_0+\beta_3)\)
- \(\beta_0\)
= \(\beta_3\)
T1 vs. T2
\((\beta_0+\beta_2)\)
-\((\beta_0+\beta_1)\)
= \(\beta_2-\beta_1\)
T1 vs. T3
\((\beta_0+\beta_3)\)
-\((\beta_0+\beta_1)\)
= \(\beta_3-\beta_1\)
T2 vs. T3
\((\beta_0+\beta_3)\)
-\((\beta_0+\beta_2)\)
= \(\beta_3 - \beta_2\)
R Code: Estimating All Group Differences in R
library(multcomp) # install.packages("multcomp")mod_e0 <-lm(Test ~ Group, data = dataTestExperiment)summary(mod_e0)
contrast_model_matrix =matrix(c(0, 1, 0, 0, # Control vs. T10, 0, 1, 0, # Control vs. T20, 0, 0, 1, # Control vs. T30, -1, 1, 0, # T1 vs. T20, -1, 0, 1, # T1 vs. T30, 0,-1, 1# T2 vs. T3), nrow =6, byrow = T)rownames(contrast_model_matrix) <-c( "Control vs. T1", "Control vs. T2", "Control vs. T3", "T1 vs. T2", "T1 vs. T3", "T2 vs. T3" ) contrast_value <-glht(mod_e0, linfct = contrast_model_matrix)summary(contrast_value)
Simultaneous Tests for General Linear Hypotheses
Fit: lm(formula = Test ~ Group, data = dataTestExperiment)
Linear Hypotheses:
Estimate Std. Error t value Pr(>|t|)
Control vs. T1 == 0 7.7600 0.7586 10.229 <0.001 ***
Control vs. T2 == 0 2.1600 0.7586 2.847 0.0275 *
Control vs. T3 == 0 6.8800 0.7586 9.069 <0.001 ***
T1 vs. T2 == 0 -5.6000 0.7586 -7.382 <0.001 ***
T1 vs. T3 == 0 -0.8800 0.7586 -1.160 0.6534
T2 vs. T3 == 0 4.7200 0.7586 6.222 <0.001 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Adjusted p values reported -- single-step method)
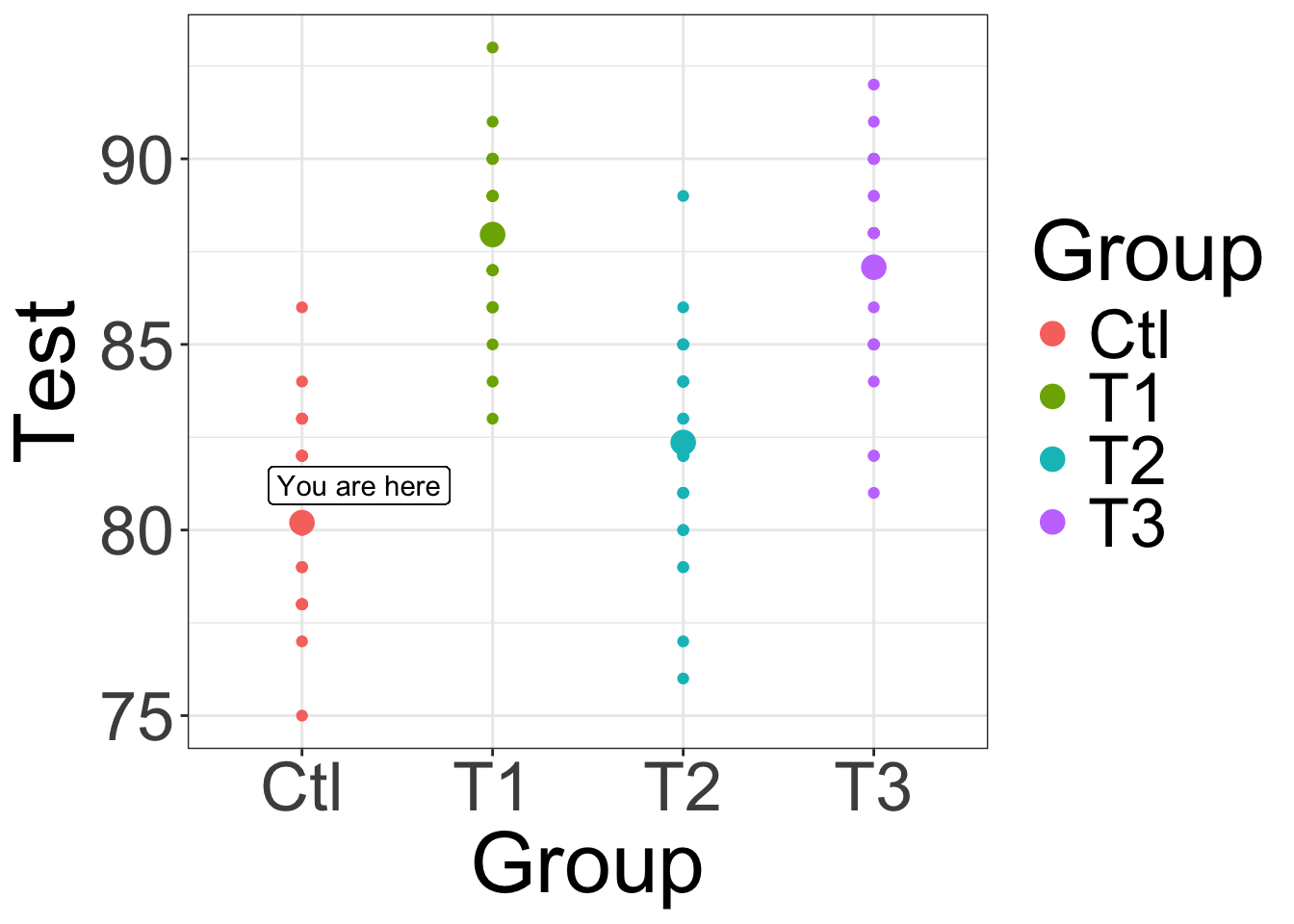
What the intercept should mean to you
The model for the means will describe what happens to the predicted outcome Y “as X increases” or “as Z increases” and so forth
But you wont what Y is actually supposed to be unless you know where the predictor variables are starting from!
Therefor, the intercept is the “YOU ARE HERE” sign in the map of your data… so it should be somewhere in the map*!
Main Effects Within Interactions
Why Interaction Effect
Interaction (Moderation) effect allows researchers to investigating more complex situations - The effect of A on C is adjusted by B.
Interaction Effects
Interaction = Moderation: the effect of a predictor depends on the value of the interacting predictor
Either predictor can be “the moderator” (interpretive distinction only)
Interaction can always be evaluated for any combination of categorical and continuous predictors, although
In “ANOVA”: By default, all possible interactions are estimated
Software does this for you; oddly enough, nonsignificant interactions usually still are kept in the model (even if only significant interactions are interpreted)
In “ANCOVA”: Continuous predictors (“covariates”) do not get to be part of interaction ➡️ make the “homogeneity of regression” assumption
There is no reason to assume this – it is a testable hypothesis!
In “Regression”: No default – effects of predictors are as you specify them
Requires most thought, but gets annoying because in regression programs you usually have to manually create the interaction as an observed variable:
e.g., XZ_interaction = centered_X * centered_Z
Simple / Conditional Main Effects in GLM with Interactions
Note
Main effects of predictors within interactions should remain in the model regardless of whether or not they are significant
Reason: the role of two-way interaction is to adjust its main effects
However, the original idea of a “main effect” no longer applied … each main effect is conditional on the interacting predictor as 0 (\(X_1X_2=0\))
Conditional Main Effect = What it is + What modified it
Simple Main Effect = The modified value of main effect
“Conditional” main effect is a general form of “Simple” main effect:
\(\beta_1\) is the “simple” main effect of X1 when X2 = 0
\(\beta_1 + \beta_3 X_2\) is the “conditional” main effect of X1 depending on X2 values
\(\beta_2\) is the “simple” main effect of X2 when X1 = 0
\(\beta_2 + \beta_3 X_1\) is the “conditional” main effect of X2 depending on X1 values
Model-Implied Simple Main Effects
To quickly compute simple main effects:
Tip
The trick is keeping track of what 0 means for every interacting predictor, which depends on the way each predictor is being represented, as determined by you, or by the software without you!
where new conditional main effect\(\beta_2^{new} = \beta_2 + \beta_3 * T\)
Quiz
Testing the Significance of Model-Implied Fixed Effects
We now know how to calculate any conditional main effect:
Effect of interest (“conditional” main effect) = what it is + what modifies it
Output Effect (“simple” main effect) = what it is + what modifies it is 0
But if we want to test whether that new effect is \(\neq 0\), we also need its standard error (SE needed to get Wald test T-value ➡️p-value)
Even if the conditional main effect is not directly given by the model, its estimate and SE are still implied by the model
3 options to get the new conditional main effect estimates and SE
Method 1: Ask the software to give it to you using your original model
e.g., glht function in R package multicomp, ESTIMATE in SAS, TEST in SPSS, NEW in Mplus
Model 2: Re-center your predictors to the interacting value of interest (e.g., make Exam = 3 the new 0 for \(\text{Exam}_C\)) and re-estimate your model; repeat as needed for each value of interest
Method 3: Hand calculations (what the program is doing for you in option #1)
Method 3 for example: Effect of Motiv = \(\beta_1 + \beta_3 * \text{Exam}\)
We have following formula to calculate the sampling error variance of “conditional” main effect as
Values come from “asymptotic (sampling) covariance matrix”
Variance of a sum of terms always includes covariance among them
Here, this is because what each main effect estimate could be is related to what the other main effect estimates could be
Note that if a main effect is unconditional, its \(SE^2 = Var(\beta)\) only
Unit 2: GLM Example 1
GLM via Dummy-Coding in “Regression”
# Model 1: 2 X 2 predictors with 0/1 codingmodel1 <-lm(Test ~ Senior + New + Senior * New, data = dataTestExperiment)# Alternativeformular_mod1 <-as.formula("Test ~ Senior + New + Senior * New")model1 <-lm(formular_mod1, data = dataTestExperiment)summary(model1)
Call:
lm(formula = formular_mod1, data = dataTestExperiment)
Residuals:
Min 1Q Median 3Q Max
-6.36 -2.08 0.04 1.83 6.64
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 80.2000 0.5364 149.513 < 2e-16 ***
Senior 2.1600 0.7586 2.847 0.00539 **
New 7.7600 0.7586 10.229 < 2e-16 ***
Senior:New -3.0400 1.0728 -2.834 0.00561 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.682 on 96 degrees of freedom
Multiple R-squared: 0.6013, Adjusted R-squared: 0.5888
F-statistic: 48.26 on 3 and 96 DF, p-value: < 2.2e-16
anova(model1)
Analysis of Variance Table
Response: Test
Df Sum Sq Mean Sq F value Pr(>F)
Senior 1 10.24 10.24 1.4235 0.235762
New 1 973.44 973.44 135.3253 < 2.2e-16 ***
Senior:New 1 57.76 57.76 8.0297 0.005609 **
Residuals 96 690.56 7.19
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Note
These ANOVA table is displaying marginal tests (F-test) for the main effects. Marginal tests are for the main effect only and are not conditional on any interacting variables.
Getting Group Means as a Contrast
We can get group means of test scores with Senior/Freshman by New/Old combination
glht() requests predicted outcomes from model for the means:
# Standard error of freshman-new groupVar_Test_1 <- Var_beta_0 <-vcov(model1)[1,1](SE_Test_1 <-sqrt(Var_Test_1))
[1] 0.5364078
# Standard error of freshman-old groupVar_beta_0 <-vcov(model1)[1,1]Var_beta_2 <-vcov(model1)[3,3]Cov_beta_0_2 <-vcov(model1)[1,3]Var_Test_2 <- Var_beta_0 + Var_beta_2 +2*Cov_beta_0_2(SE_Test_2 <-sqrt(Var_Test_2))
[1] 0.5364078
Your Homework 1 - Question 1
Copy and paste your R syntax abd output that calculates the Senior-Old’s standard errors of means (use the data and model we use in class). For example, our class syntax for Freshman-New is like:
We can use glht() to automatically calculate conditional main effects and their standard errors. Or, we can manually calculate them using vcov(model) function, which represents the variance-covariance matrix of main effects.
Method 1: glht method
effect_model1_matrix =matrix(c(0, 1, 0, 0, # Senior vs. Freshmen | Old0, 1, 0, 1, # Senior vs. Freshmen | New0, 0, 1, 0, # New vs. Old | Freshmen0, 0, 1, 1# New vs. Old | Senior), nrow =4, byrow = T)rownames(effect_model1_matrix) <-c( "beta_Senior_New0", # Conditional Main Effect of Senior given New = 0"beta_Senior_New1", # Conditional Main Effect of Senior given New = 1"beta_New_Senior0", # Conditional Main Effect of New given Senior = 0"beta_New_Senior1") # Conditional Main Effect of New given Senior = 1effect_model1 <-glht(model1, linfct = effect_model1_matrix)summary(effect_model1)
Simultaneous Tests for General Linear Hypotheses
Fit: lm(formula = formular_mod1, data = dataTestExperiment)
Linear Hypotheses:
Estimate Std. Error t value Pr(>|t|)
beta_Senior_New0 == 0 2.1600 0.7586 2.847 0.0196 *
beta_Senior_New1 == 0 -0.8800 0.7586 -1.160 0.5939
beta_New_Senior0 == 0 7.7600 0.7586 10.229 <0.001 ***
beta_New_Senior1 == 0 4.7200 0.7586 6.222 <0.001 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Adjusted p values reported -- single-step method)
Method 2: vcov method
Example: Conditional main effectof Senior\(\mathbf{\beta_1^{Senior}}\) (Senior vs. Freshmen) when using the new method (New = 1)
Var_beta_1 =vcov(model1)[2,2] # squared SE of beta1Var_beta_3 =vcov(model1)[4,4] # squared SE of beta3Cov_beta_1_3 =vcov(model1)[4,2] # residual covariance of beta1 and beta3Var_beta_1_new <- Var_beta_1 + Var_beta_3 *1+2* Cov_beta_1_3 *1(SE_beta_1_new <-sqrt(Var_beta_1_new))
[1] 0.7585952
Your Homework 1 - Question 2
Copy and paste your R syntax and output that calculates the standard error of conditional main effect of New (New vs. Old) when Senior = 1. For example, standard error of conditional main effect of Senior when New = 1 is like: