flowchart RL
A("Model:
Substantive Theory") --> |Hypothesized Causal Process|B("Observed Outcomes
(any format)")
Lecture 06: Generalized Linear Models (Binary Outcome) and Matrix Algebra
Generalized Linear Models
2024-09-24
Common distributions and canonical link functions (from Wikipedia)
| Distribution | Support of distribution | Typical uses | Link name | Link function | Mean function |
| Normal | real: | Linear-response data | Identity | ||
| Exponential | real: | Exponential-response data, scale parameters | Negative inverse | ||
| Gamma | |||||
| Inverse Gaussian |
real: | Inverse squared |
|||
| Poisson | integer: | count of occurrences in fixed amount of time/space | Log | ||
| Bernoulli | integer: | outcome of single yes/no occurrence | Logit | ||
| Binomial | integer: | count of # of "yes" occurrences out of N yes/no occurrences | |||
| Categorical | integer: | outcome of single K-way occurrence | |||
| K-vector of integer: , where exactly one element in the vector has the value 1 | |||||
| Multinomial | K-vector of integer: | count of occurrences of different types (1, ..., K) out of N total K-way occurrences |


















![{\displaystyle [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)
![{\displaystyle [0,N]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/703d57dca548a7f9d927247c2a27b67666aebdd5)
A General Linear Model With Binary Outcomes?
How can we have a linear relationship between X & Y?
Probability of a 1 is bounded between 0 and 1, but predicted probabilities from a linear model aren’t bounded
- Impossible values
Linear relationship needs to ‘shut off’ somehow \(\rightarrow\) made nonlinear
Predicted Regression Line of GLM
Code
library(ggplot2)
ggplot(dataLogit) +
aes(x = GPA, y = LLAPPLY) +
geom_hline(aes( yintercept = 1)) +
geom_hline(aes( yintercept = 0)) +
geom_point(color = "tomato", alpha = .8) +
geom_smooth(method = "lm", se = FALSE, fullrange = TRUE, linewidth = 1.3) +
scale_x_continuous(limits = c(0, 8), breaks = 0:8) +
scale_y_continuous(limits = c(-0.4, 1.4), breaks = seq(-0.4, 1.4, .1)) +
labs(y = "Predicted Probability of Y") +
theme_classic() +
theme(text = element_text(size = 20))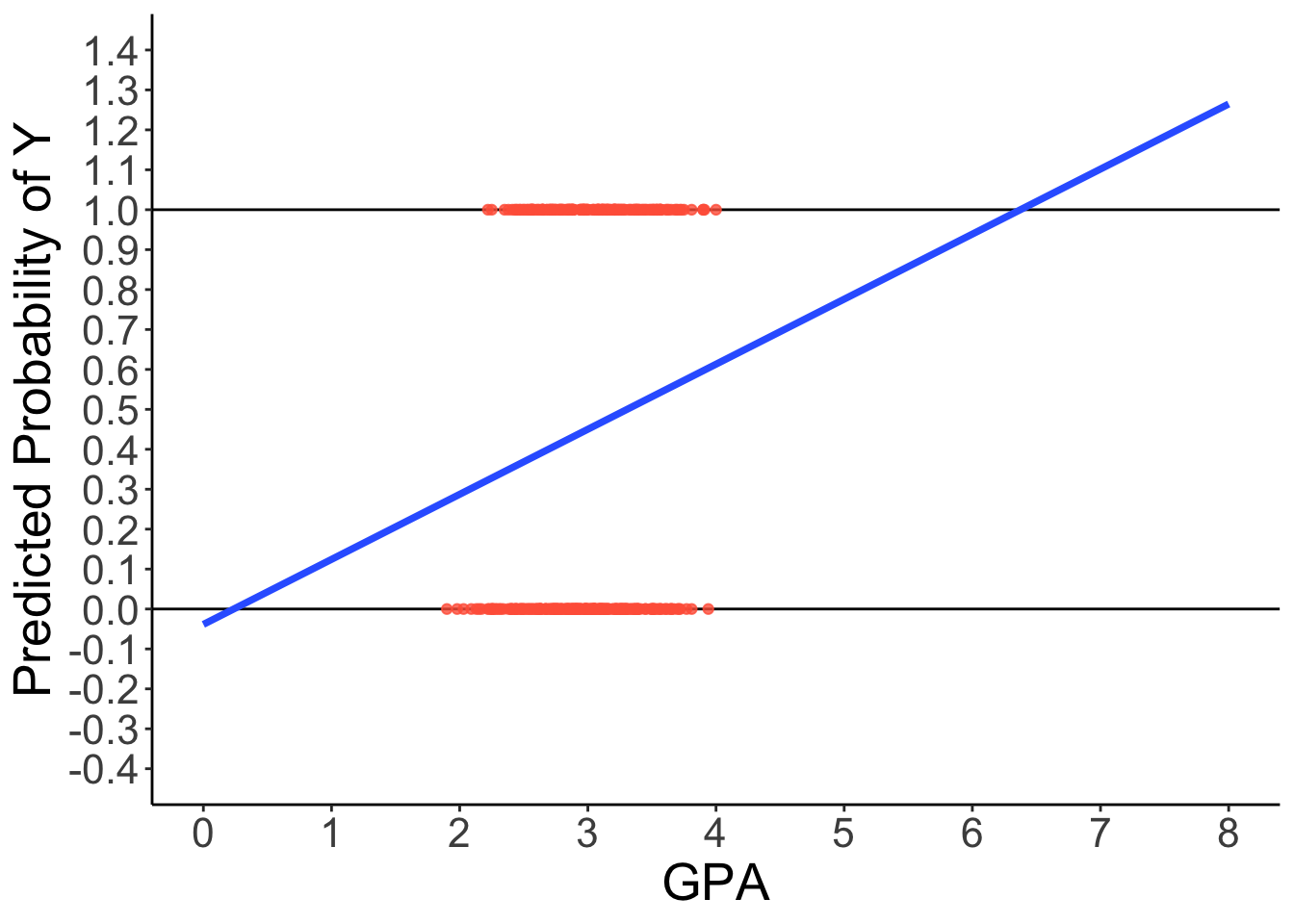
Predicted Regression Line of Logistic Regression
Code
ggplot(dataLogit) +
aes(x = GPA, y = LLAPPLY) +
geom_hline(aes( yintercept = 1)) +
geom_hline(aes( yintercept = 0)) +
geom_point(color = "tomato", alpha = .8) +
geom_smooth(method = "glm", se = FALSE, fullrange = TRUE,
method.args = list(family = binomial(link = "logit")), color = "yellowgreen", linewidth = 1.5) +
scale_x_continuous(limits = c(0, 8), breaks = 0:8) +
scale_y_continuous(limits = c(-0.4, 1.4), breaks = seq(-0.4, 1.4, .1)) +
labs(y = "Predicted Probability of Y") +
theme_classic() +
theme(text = element_text(size = 20))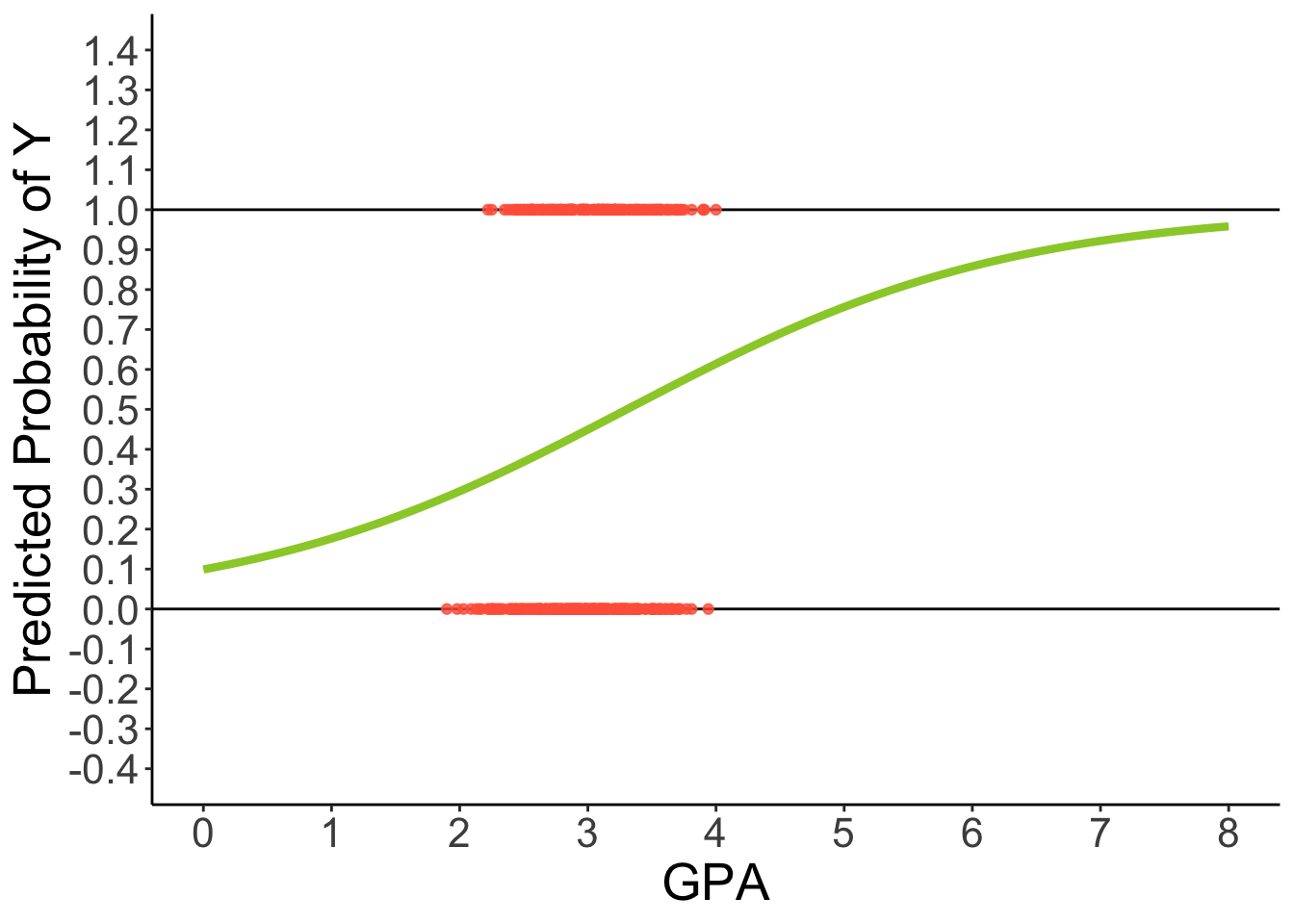
Slope of GPA3: \(\beta_2(SE) = 0.5482 (0.2724)\) with \(p < .05\)
Interpretation
- For every one-unit increase in GPA, the logit of applying for grad. school will increase 0.548, the odds ratio will be 1.73 times, the probabilities will be 19.2%, 29.2%, 41.6% to 55.2% for GPA = 1 , 2, 3 and 4
new_data <- data.frame(
GPA3 = seq(-3, 1, .1),
PARED = 0,
PUBLIC = 0
)
Pred_prob <- predict(model1, newdata=new_data)$fit
as.data.frame(cbind(GPA = new_data$GPA3+3, P_Y_0 = Pred_prob[,1], P_Y_1 = Pred_prob[,2])) |>
pivot_longer(starts_with("P_Y")) |>
ggplot() +
aes(x = GPA, y = value) +
geom_path(aes(group = name, color = name), linewidth = 1.3) +
labs(y = "Predicted Probability") +
scale_x_continuous(breaks = seq(0, 4, .2)) +
scale_color_discrete(labels = c("P(Y = 0)", "P(Y = 1)"), name = "") +
theme_classic()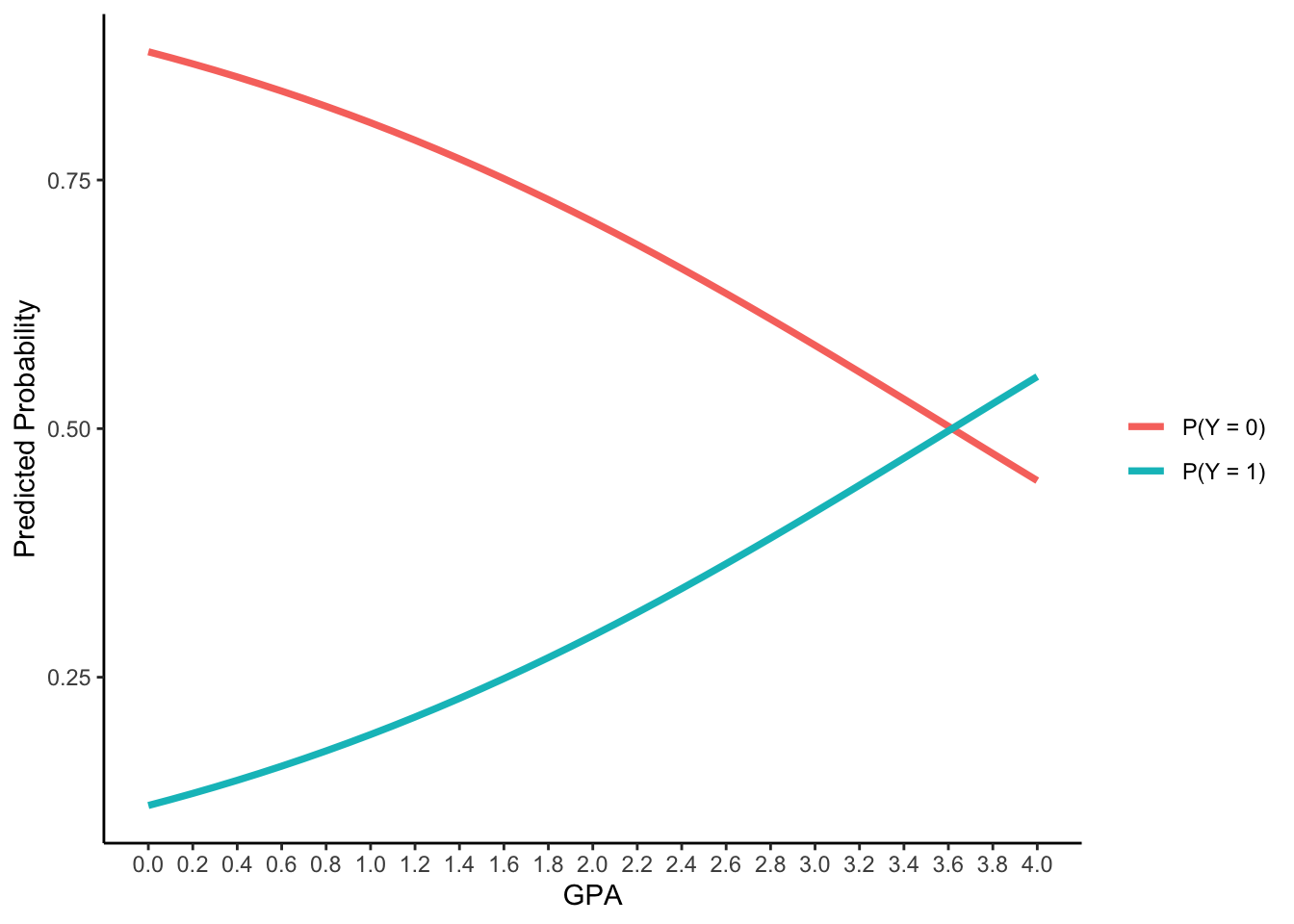
Takehome Note
- For logistic models with two responses:
- Regression weights are now for LOGITS
- The direction of what is being modeled has to be understood (Y = 0 or = 1)
- The change in odds and probability is not linear per unit change in the IV, but instead is linear with respect to the logit
- Interactions will still
- Will still modify the conditional main effects
- Simple main effects are effects when interacting variables = 0
Wrap up
Generalized linear models are models for outcomes with distributions that are not necessarily normal
The estimation process is largely the same: maximum likelihood is still the gold standard as it provides estimates with understandable properties
Learning about each type of distribution and link takes time:
- They all are unique and all have slightly different ways of mapping outcome data onto your model
Logistic regression is one of the more frequently used generalized models – binary outcomes are common
![]()