[1] 0.6Lecture 11: Introduction to Bayesian Statistics and Markov Chain Monte Carlo Estimation
2024-10-09
What is Bayesian?
- A statistical inference based on Bayesian Probability Theory to estimate uncertainty
What are key components of Bayesian models?
- Likelihood function - likelihood of data given assumed probability distribution
- Prior distribution - belief / previous evidences of parameters
- Posterior distribution - updated information of parameters given our data and modeling
- Posterior predictive distribution - future / predicted data
What are the differences between Bayesian with Frequentist analysis?
- Input: prior distribution: Bayesian vs. hypothesis of fixed parameters: frequentist
- Estimation process: Markov Chain Monte Carlo (MCMC) vs. Maximum Likelihood Estimation (MLE)
- Result: posterior distribution vs. point estimates of parameters
- Accuracy check: credible interval (plausibility of the parameters having those values) vs. confidence interval (the proportion of infinite samples having the fixed parameters)
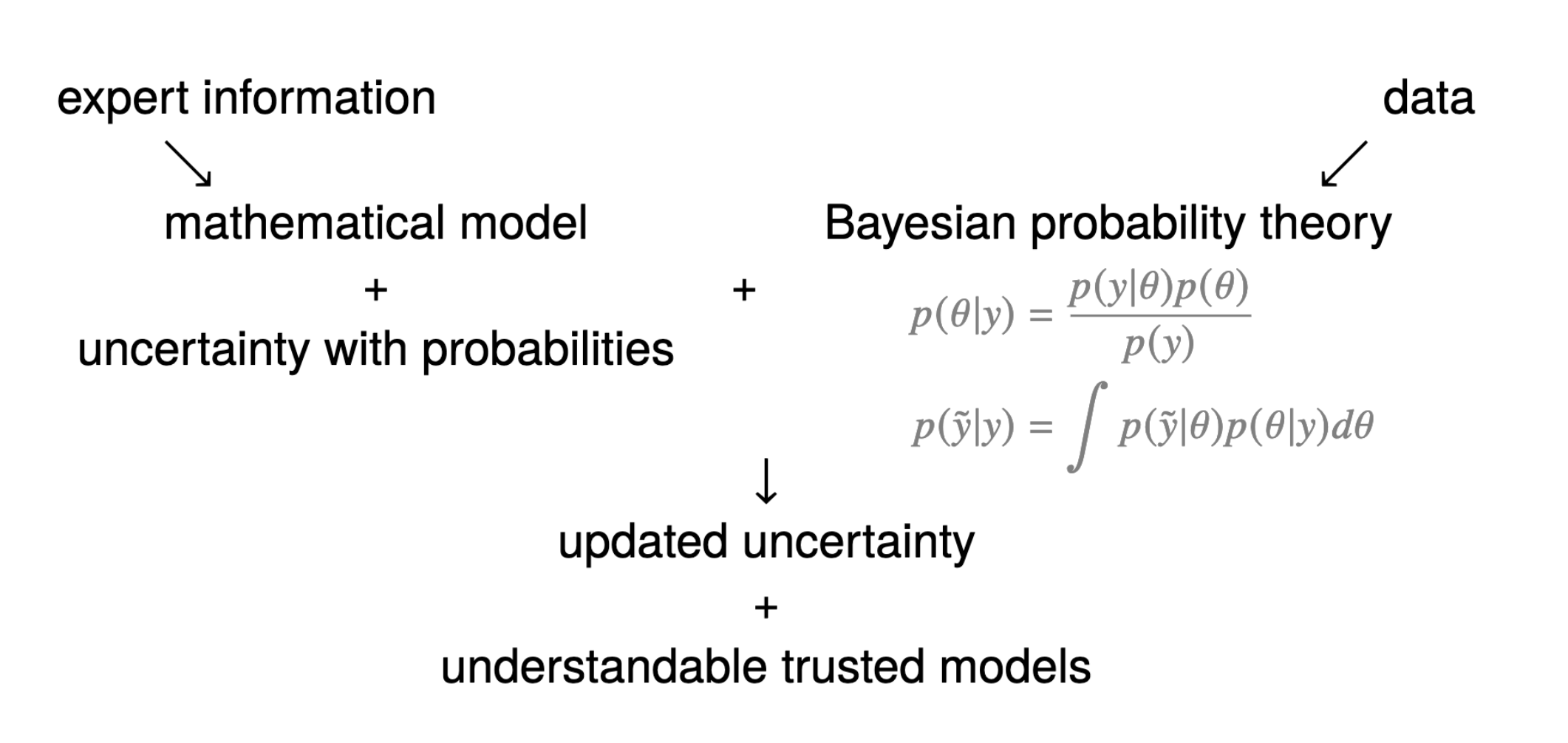
Log-likelihood Function across different values of Parameter
\[ LL(p_1, Data =\{0, 1, 0, 1, 1\}) \]
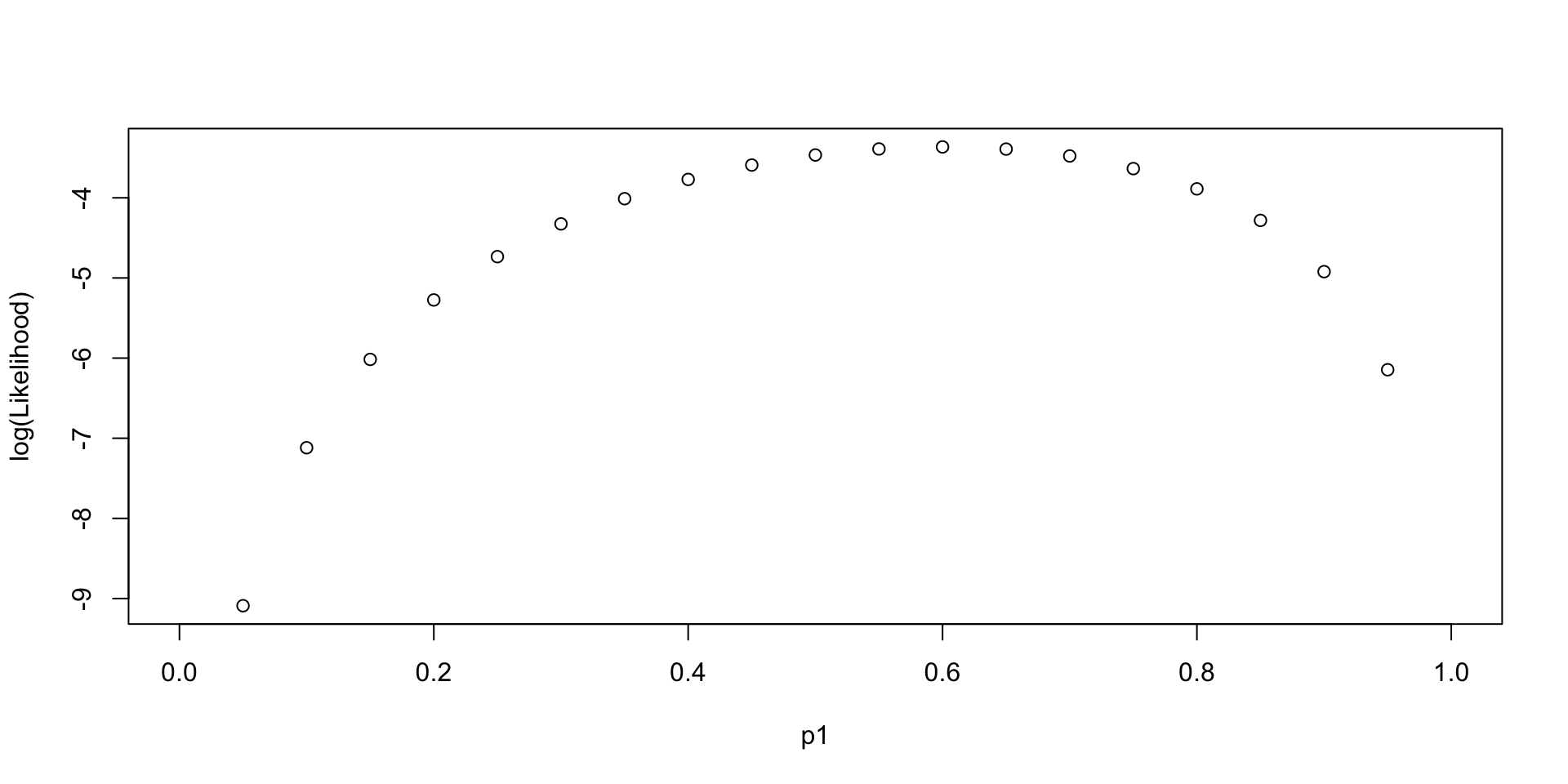
Log-likelihood Function given different Data sets
\[ LL(p_1 \in \{0, 0.2,0.4, 0.6, 0.8,1\}, Data \in \{0/5, 1/5, 2/5, 3/5, 4/5, 5/5\}) \]
Code
library(tidyverse)
p1 = c(0, 2, 4, 6, 8, 10) / 10
nTrails = 5
nSuccess = 0:nTrails
Likelihood = sapply(p1, \(x) choose(nTrails,nSuccess)*(x)^nSuccess*(1-x)^(nTrails - nSuccess))
Likelihood_forPlot <- as.data.frame(Likelihood)
colnames(Likelihood_forPlot) <- p1
Likelihood_forPlot$Sample = factor(paste0(nSuccess, " out of ", nTrails), levels = paste0(nSuccess, " out of ", nTrails))
# plot
Likelihood_forPlot %>%
pivot_longer(-Sample, names_to = "p1") %>%
mutate(`log(Likelihood)` = log(value)) %>%
ggplot(aes(x = Sample, y = `log(Likelihood)`, color = p1)) +
geom_point(size = 2) +
geom_path(aes(group=p1), size = 1.3)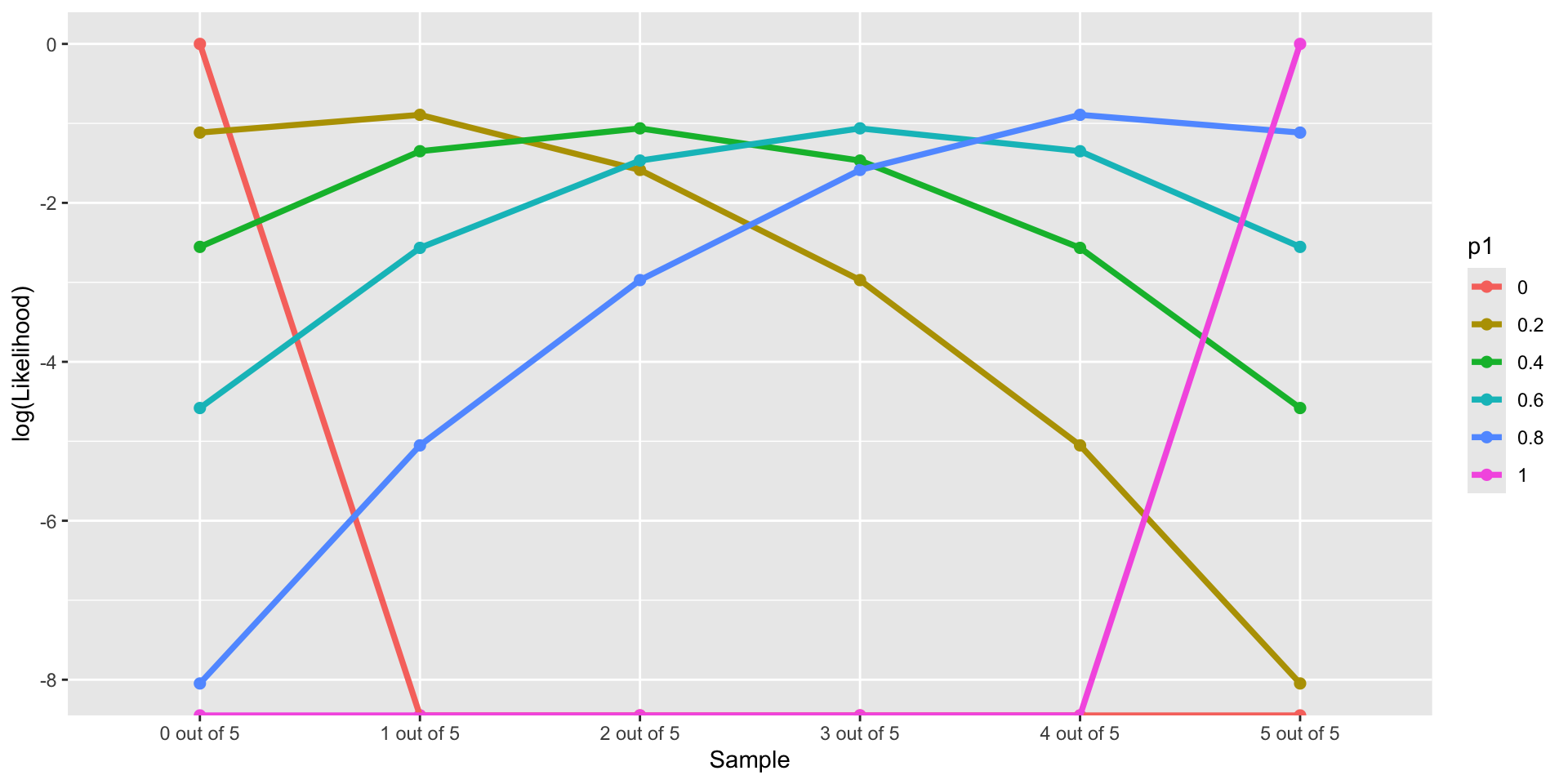
More nice properties: Beta Distribution
The Beta distribution has a mean of \(\frac{\alpha}{\alpha+\beta}\) and a mode of \(\frac{\alpha -1}{\alpha + \beta -2}\) for \(\alpha > 1\) & \(\beta > 1\); (fun fact: when \(\alpha\ \&\ \beta< 1\), pdf is U-shape, what that mean?)
\(\alpha\) and \(\beta\) are called hyperparameters of the parameter \(p_1\);
Hyperparameters are parameters of prior parameters ;
When \(\alpha = \beta = 1\), the distribution is uniform distribution;
To make sure \(P(p_1 = \frac{1}{6})\) is the largest, we can:
Many choices: \(\alpha =2\) and \(\beta = 6\) has the same mode as \(\alpha = 100\) and \(\beta = 496\); (hint: \(\beta = 5\alpha - 4\))
The differences between choices is how strongly we feel in our beliefs
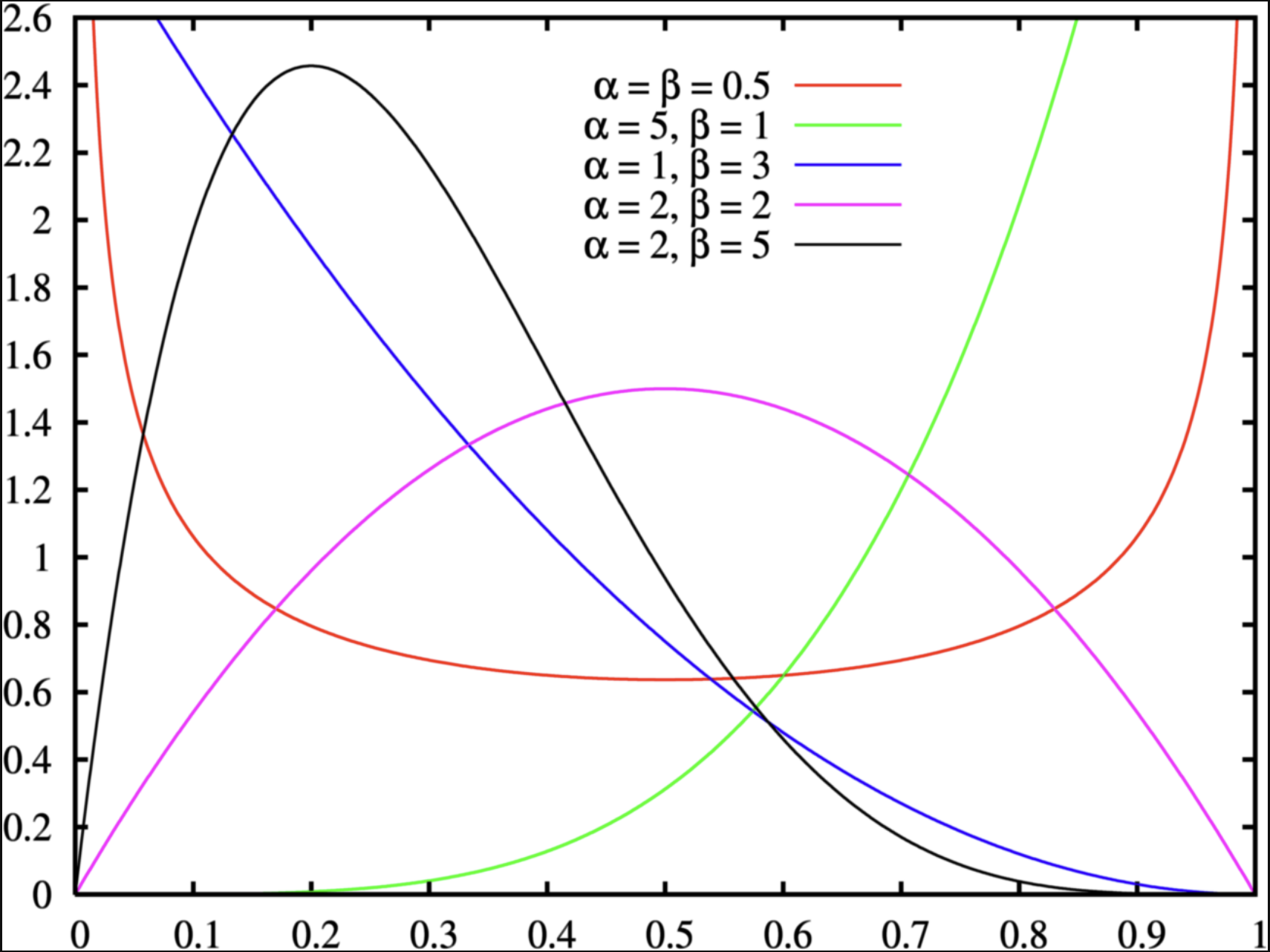
How strongly we believe in the prior
- The Beta distribution has a variance of \(\frac{\alpha\beta}{(\alpha+\beta)^2 (\alpha + \beta + 1)}\)
- The smaller prior variance means the prior is more informative
- Informative priors are those that have relatively small variances
- Uninformative priors are those that have relatively large variances
- Suppose we have four sets of hyperparameters choices: (2,6);(20,96);(100,496);(200,996)
Code
# Function for variance of Beta distribution
varianceFun = function(alpha_beta){
alpha = alpha_beta[1]
beta = alpha_beta[2]
return((alpha * beta)/((alpha + beta)^2*(alpha + beta + 1)))
}
# Multiple prior choices from uninformative to informative
alpha_beta_choices = list(
I_dont_trust = c(2, 6),
not_strong = c(20, 96),
litte_strong = c(100, 496),
very_strong = c(200, 996))
## Transform to data.frame for plot
alpha_beta_variance_plot <- t(sapply(alpha_beta_choices, varianceFun)) %>%
as.data.frame() %>%
pivot_longer(everything(), names_to = "Degree", values_to = "Variance") %>%
mutate(Degree = factor(Degree, levels = unique(Degree))) %>%
mutate(Alpha_Beta = c(
"(2, 6)",
"(20, 96)",
"(100, 496)",
"(200, 996)"
))
alpha_beta_variance_plot %>%
ggplot(aes(x = Degree, y = Variance)) +
geom_col(aes(fill = Degree)) +
geom_text(aes(label = Alpha_Beta), size = 6) +
labs(title = "Variances along difference choices of alpha and beta") +
theme(text = element_text(size = 21)) 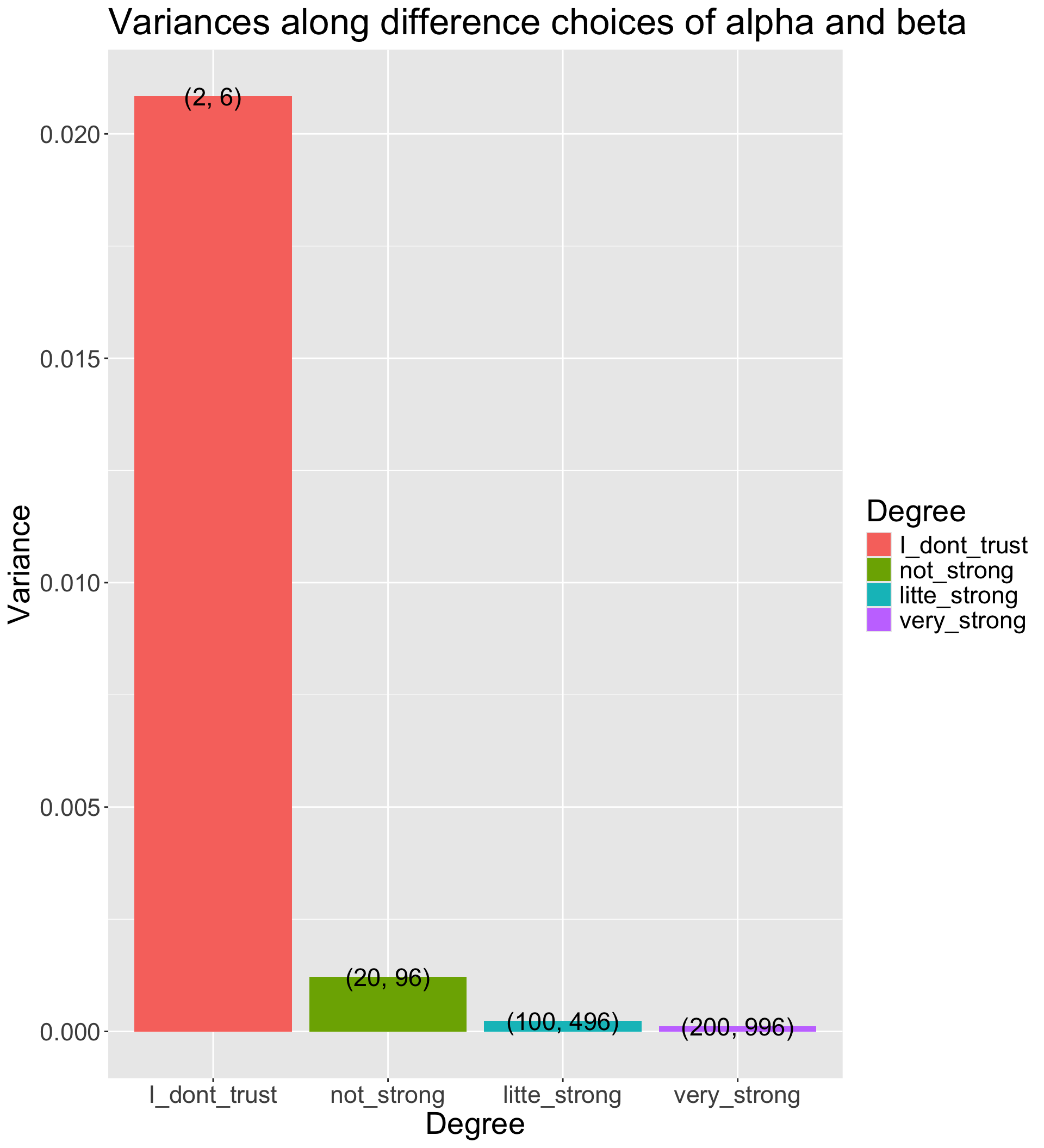
Visualize prior distribution \(P(p_1)\)
Code
dbeta <- function(p1, alpha, beta) {
# probability density function
PDF = ((p1)^(alpha-1)*(1-p1)^(beta-1)) / beta(alpha, beta)
return(PDF)
}
condition <- data.frame(
alpha = c(2, 20, 100, 200),
beta = c(6, 96, 496, 996)
)
pdf_bycond <- condition %>%
nest_by(alpha, beta) %>%
mutate(data = list(
dbeta(p1 = (1:99)/100, alpha = alpha, beta = beta)
))
## prepare data for plotting pdf by conditions
pdf_forplot <- Reduce(cbind, pdf_bycond$data) %>%
t() %>%
as.data.frame() ## merge conditions together
colnames(pdf_forplot) <- (1:99)/100 # add p1 values as x-axis
pdf_forplot <- pdf_forplot %>%
mutate(Alpha_Beta = c( # add alpha_beta conditions as colors
"(2, 6)",
"(20, 96)",
"(100, 496)",
"(200, 996)"
)) %>%
pivot_longer(-Alpha_Beta, names_to = 'p1', values_to = 'pdf') %>%
mutate(p1 = as.numeric(p1),
Alpha_Beta = factor(Alpha_Beta,levels = unique(Alpha_Beta)))
pdf_forplot %>%
ggplot() +
geom_vline(xintercept = 0.17, col = "black") +
geom_point(aes(x = p1, y = pdf, col = Alpha_Beta)) +
geom_path(aes(x = p1, y = pdf, col = Alpha_Beta, group = Alpha_Beta)) +
scale_color_discrete(name = "Prior choices")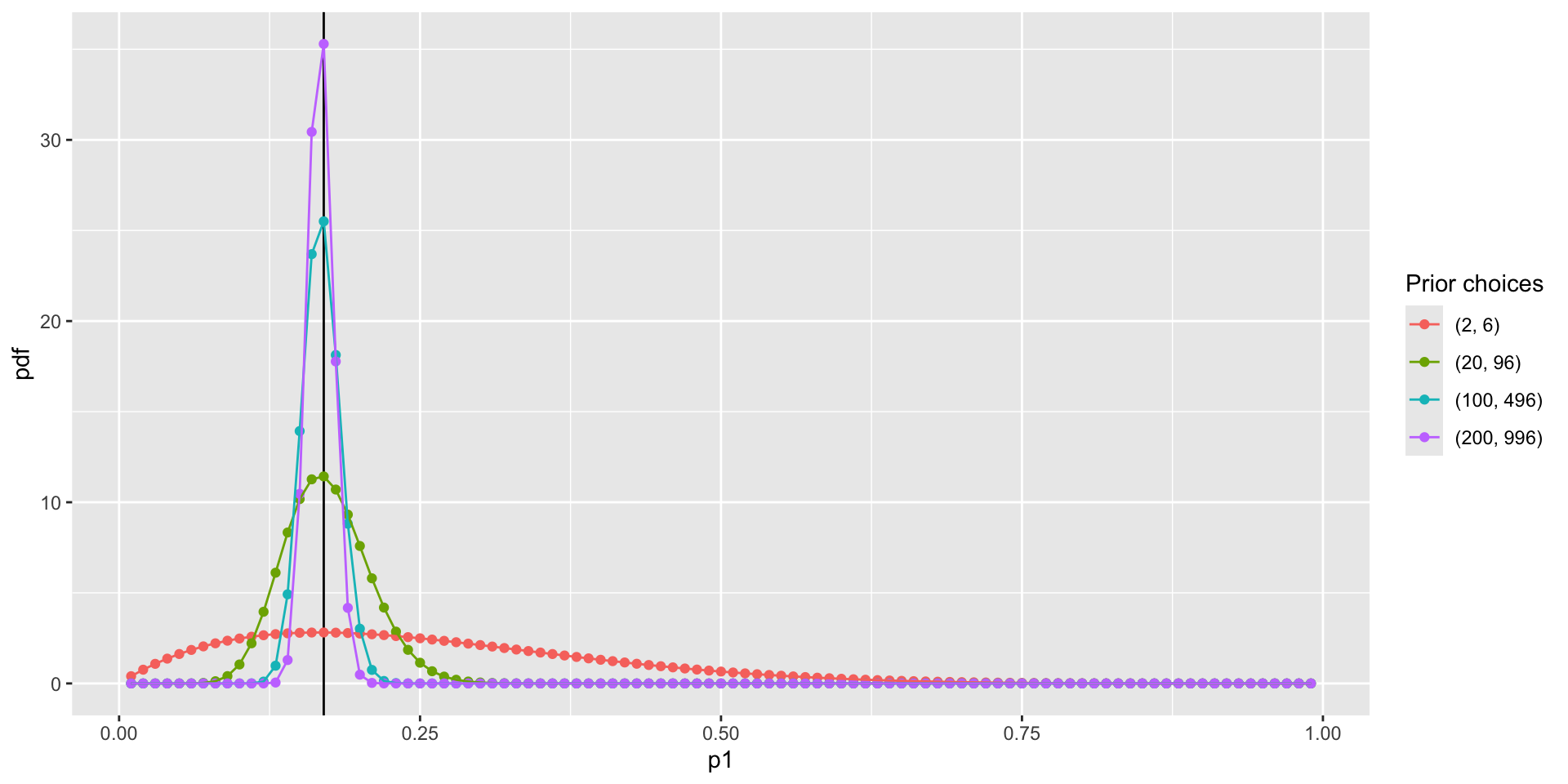
Question: WHY NOT USE NORMAL DISTRIBUTION?
Visualize the posterior distribution \(P(p_1|Data)\)
Code
dbeta_posterior <- function(p1, alpha, beta, data) {
alpha_new = alpha + sum(data)
beta_new = beta + (length(data) - sum(data) )
# probability density function
PDF = ((p1)^(alpha_new-1)*(1-p1)^(beta_new-1)) / beta(alpha_new, beta_new)
return(PDF)
}
# Observed data
dat = c(0, 1, 0, 1, 1)
condition <- data.frame(
alpha = c(2, 20, 100, 200),
beta = c(6, 96, 496, 996)
)
pdf_posterior_bycond <- condition %>%
nest_by(alpha, beta) %>%
mutate(data = list(
dbeta_posterior(p1 = (1:99)/100, alpha = alpha, beta = beta,
data = dat)
))
## prepare data for plotting pdf by conditions
pdf_posterior_forplot <- Reduce(cbind, pdf_posterior_bycond$data) %>%
t() %>%
as.data.frame() ## merge conditions together
colnames(pdf_posterior_forplot) <- (1:99)/100 # add p1 values as x-axis
pdf_posterior_forplot <- pdf_posterior_forplot %>%
mutate(Alpha_Beta = c( # add alpha_beta conditions as colors
"(2, 6)",
"(20, 96)",
"(100, 496)",
"(200, 996)"
)) %>%
pivot_longer(-Alpha_Beta, names_to = 'p1', values_to = 'pdf') %>%
mutate(p1 = as.numeric(p1),
Alpha_Beta = factor(Alpha_Beta,levels = unique(Alpha_Beta)))
pdf_posterior_forplot %>%
ggplot() +
geom_vline(xintercept = 0.17, col = "black") +
geom_point(aes(x = p1, y = pdf, col = Alpha_Beta)) +
geom_path(aes(x = p1, y = pdf, col = Alpha_Beta, group = Alpha_Beta)) +
scale_color_discrete(name = "Prior choices") +
labs( y = '')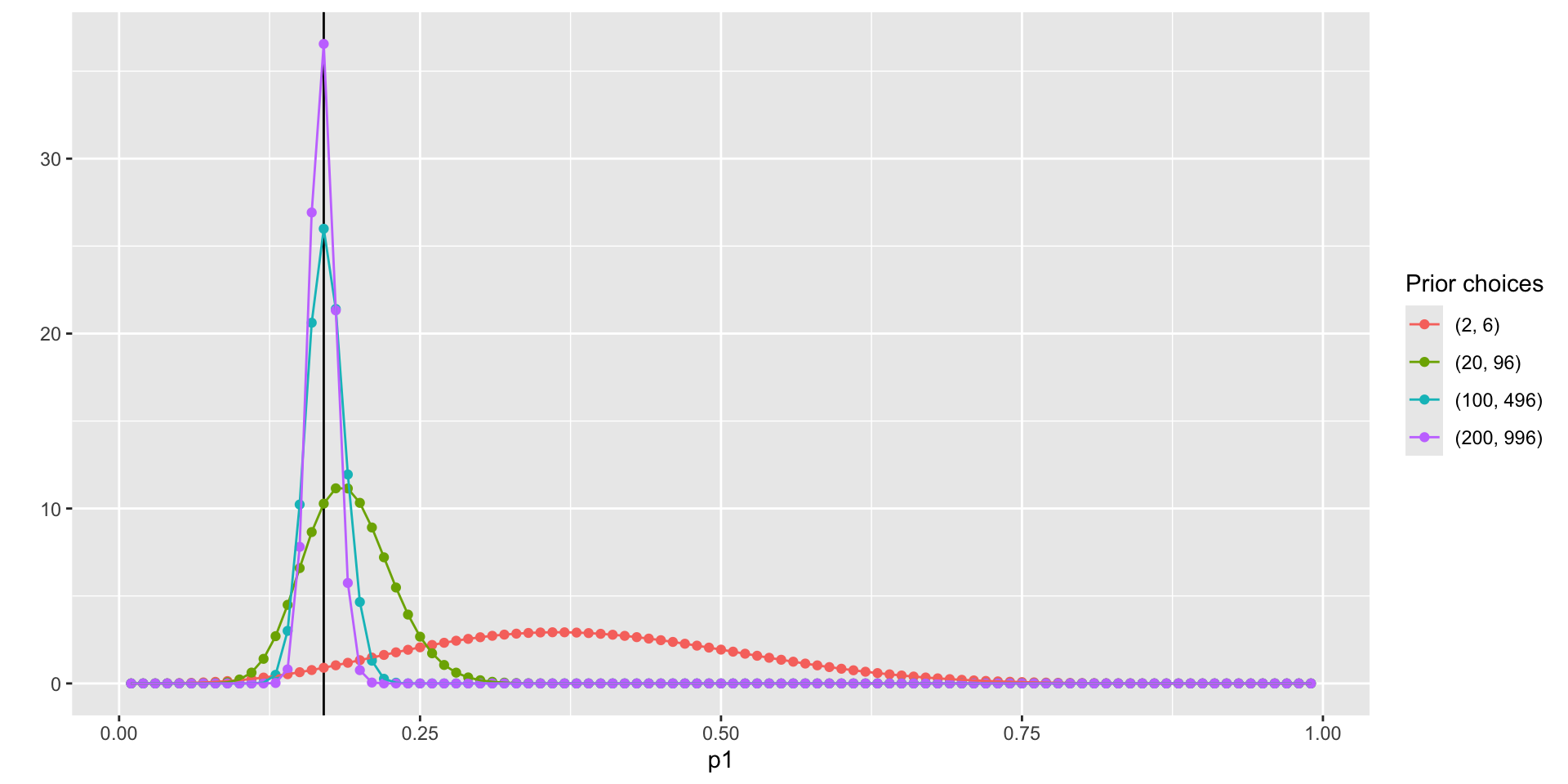
Stan and Rstudio
Option 1: Stan has its own syntax which can be built in stand-alone text files (.stan)
Rstudio will let you create a stan file in the new
FilemenuRstudio also has syntax highlighting in Stan files
Save
.stanto the same path of your.r
Option 2: You can also use Stan in a interactive way in qmd file
- Which is helpful when you want to test multiple stan models and report your results at the same time
Uninformative prior distribution (2, 6) and posterior distribution
Code
bayesplot::mcmc_dens(fit1$draws('p1')) +
geom_path(aes(x = p1, y = pdf), data = pdf_posterior_forplot %>% filter(Alpha_Beta == '(2, 6)'), col = "red") +
geom_vline(xintercept = 1/6, col = "green") +
geom_vline(xintercept = 3/5, col = "purple") +
labs(title = "Posterior distribution using uninformative prior vs. the conjugate prior (The Gibbs sampler) method", caption = 'Green: mode of prior distribution; Purple: expected value from observed data; Red: Gibbs sampling method')# A tibble: 2 × 10
variable mean median sd mad q5 q95 rhat ess_bulk ess_tail
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 lp__ -9.19 -8.91 0.751 0.337 -10.7 -8.66 1.00 1812. 2400.
2 p1 0.383 0.377 0.131 0.137 0.180 0.609 1.00 1593. 1629.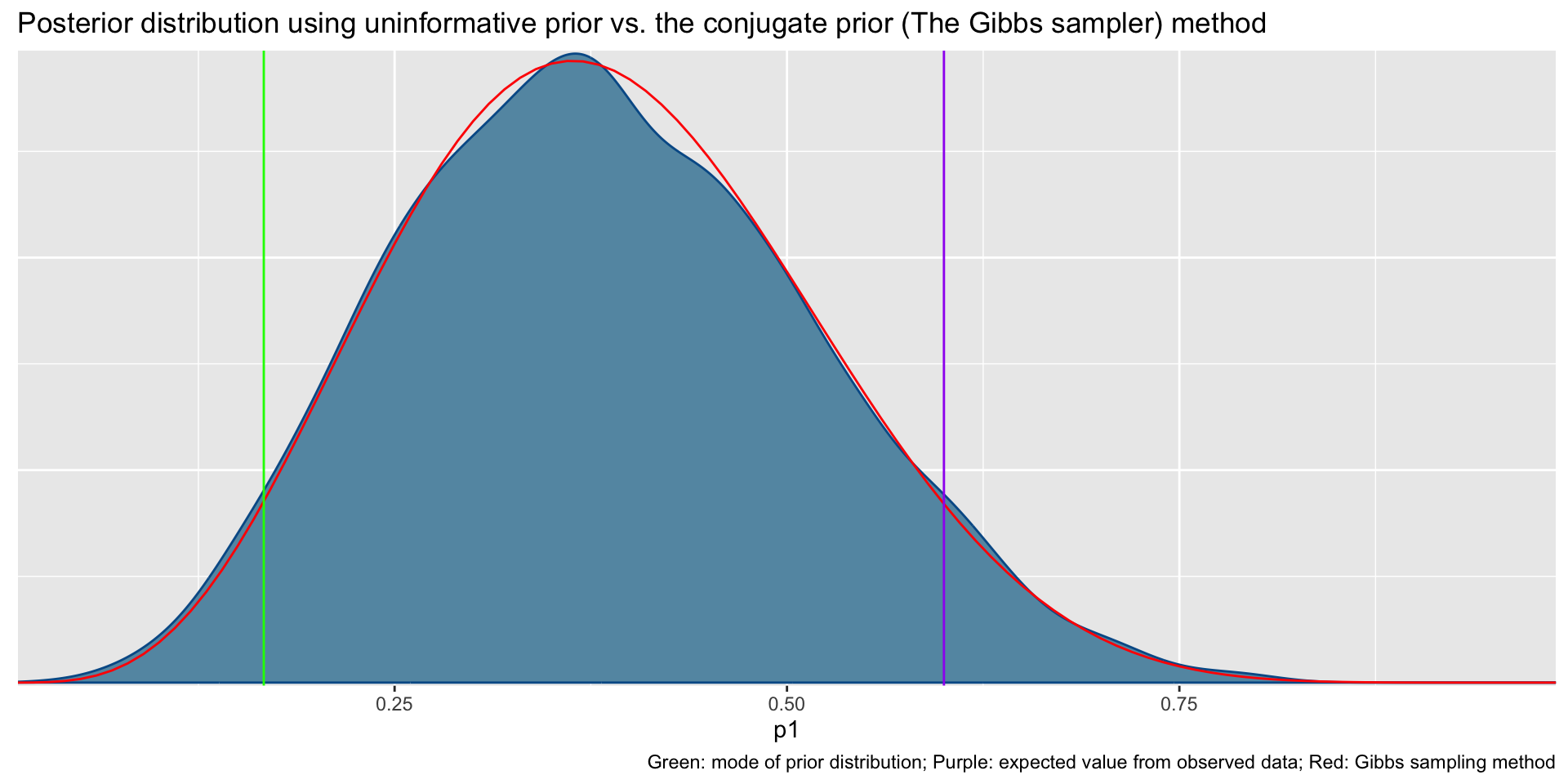
Informative prior distribution (100, 496) and posterior distribution
Code
bayesplot::mcmc_dens(fit2$draws('p1')) +
geom_path(aes(x = p1, y = pdf), data = pdf_posterior_forplot %>% filter(Alpha_Beta == '(100, 496)'), col = "red") +
geom_vline(xintercept = 1/6, col = "green") +
geom_vline(xintercept = 3/5, col = "purple") +
labs(title = "Posterior distribution using informative prior vs. the conjugate prior (The Gibbs sampler) method", caption = 'Green: mode of prior distribution; Purple: expected value from observed data; Red: Gibbs sampling method')# A tibble: 2 × 10
variable mean median sd mad q5 q95 rhat ess_bulk
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 lp__ -276. -276. 0.716 0.317 -277. -275. 1.00 1816.
2 p1 0.171 0.171 0.0154 0.0155 0.146 0.197 1.00 1627.
# ℹ 1 more variable: ess_tail <dbl>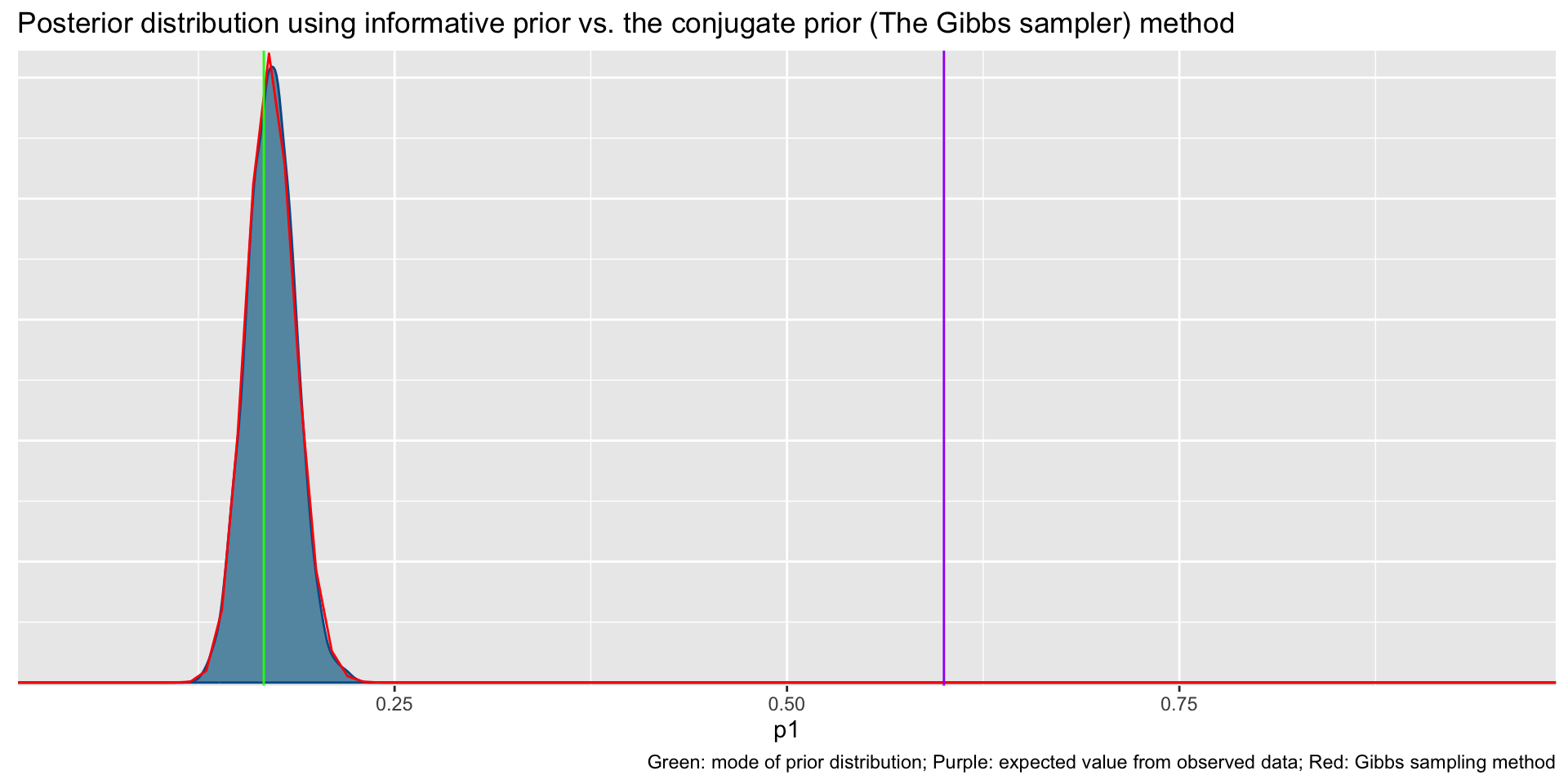
Results of Bayesian Empty Model
# A tibble: 3 × 3
variable mean rhat
<chr> <dbl> <dbl>
1 lp__ -87.2 1.00
2 beta0 183. 1.00
3 sigma 60.2 1.00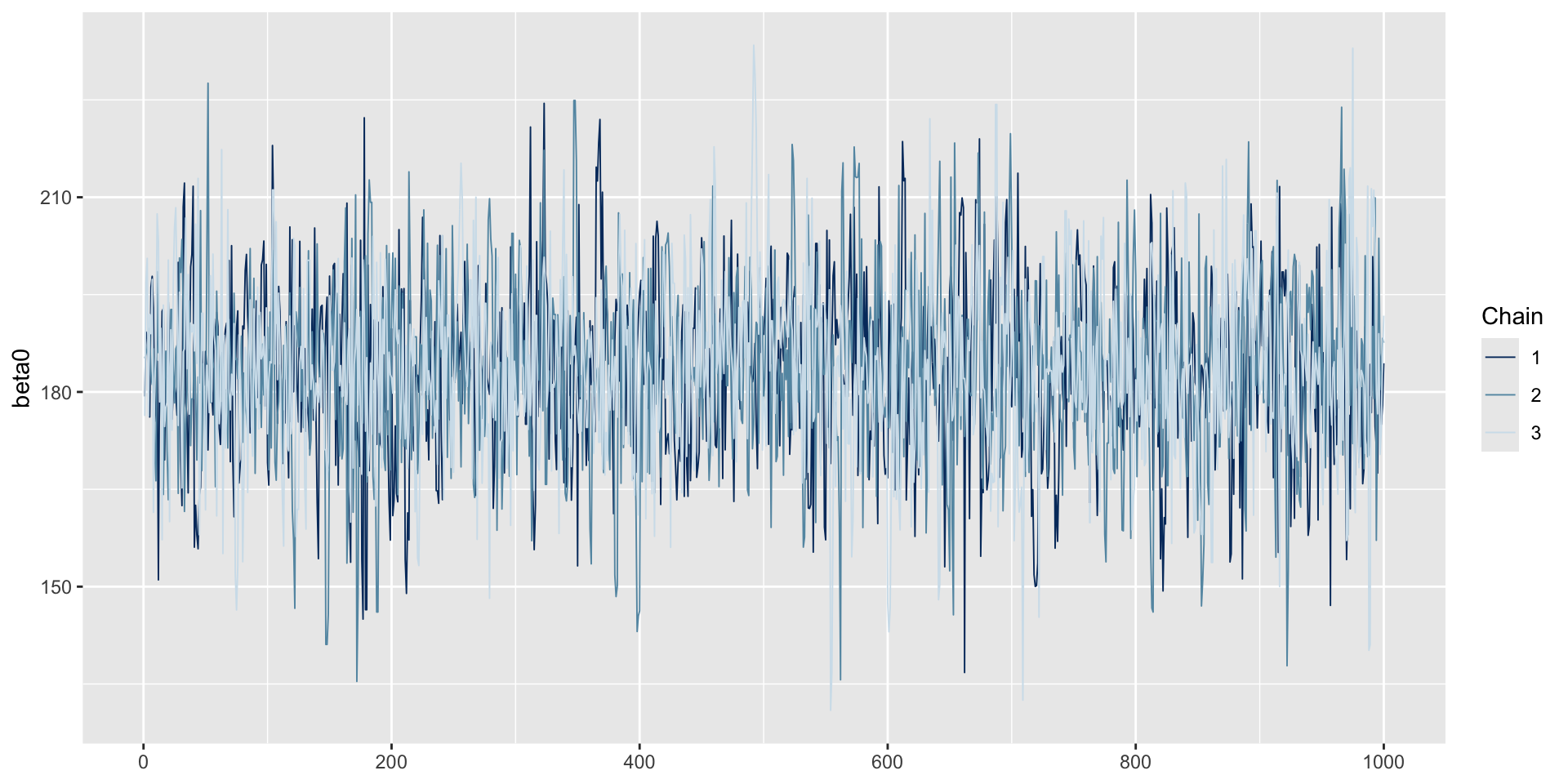
Bayesian full model using blavaan
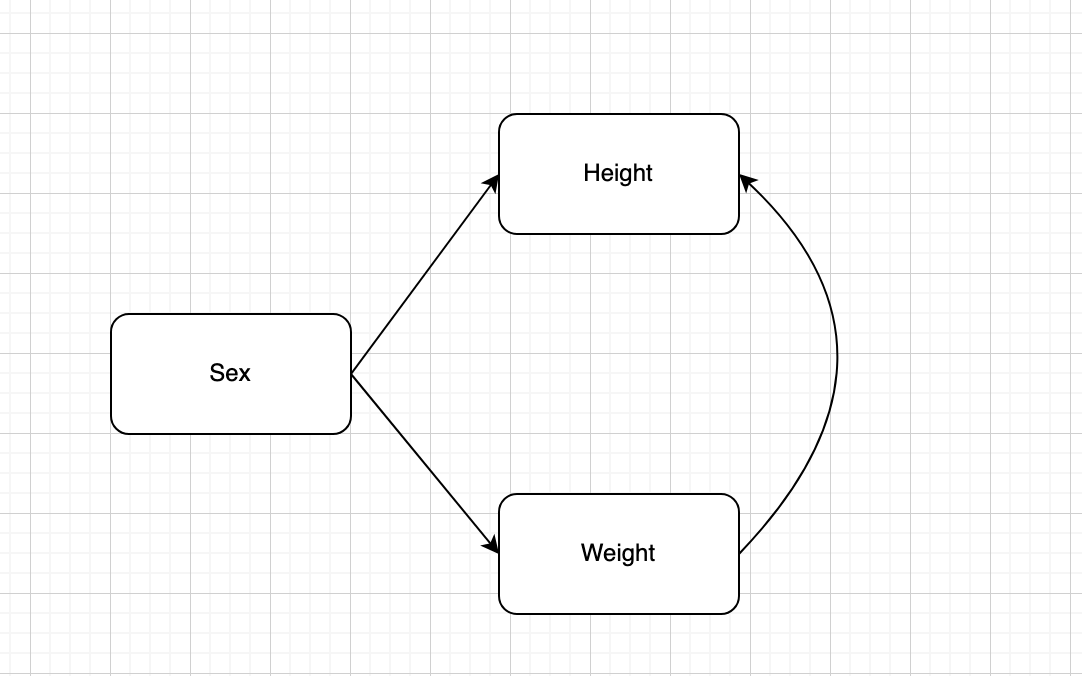
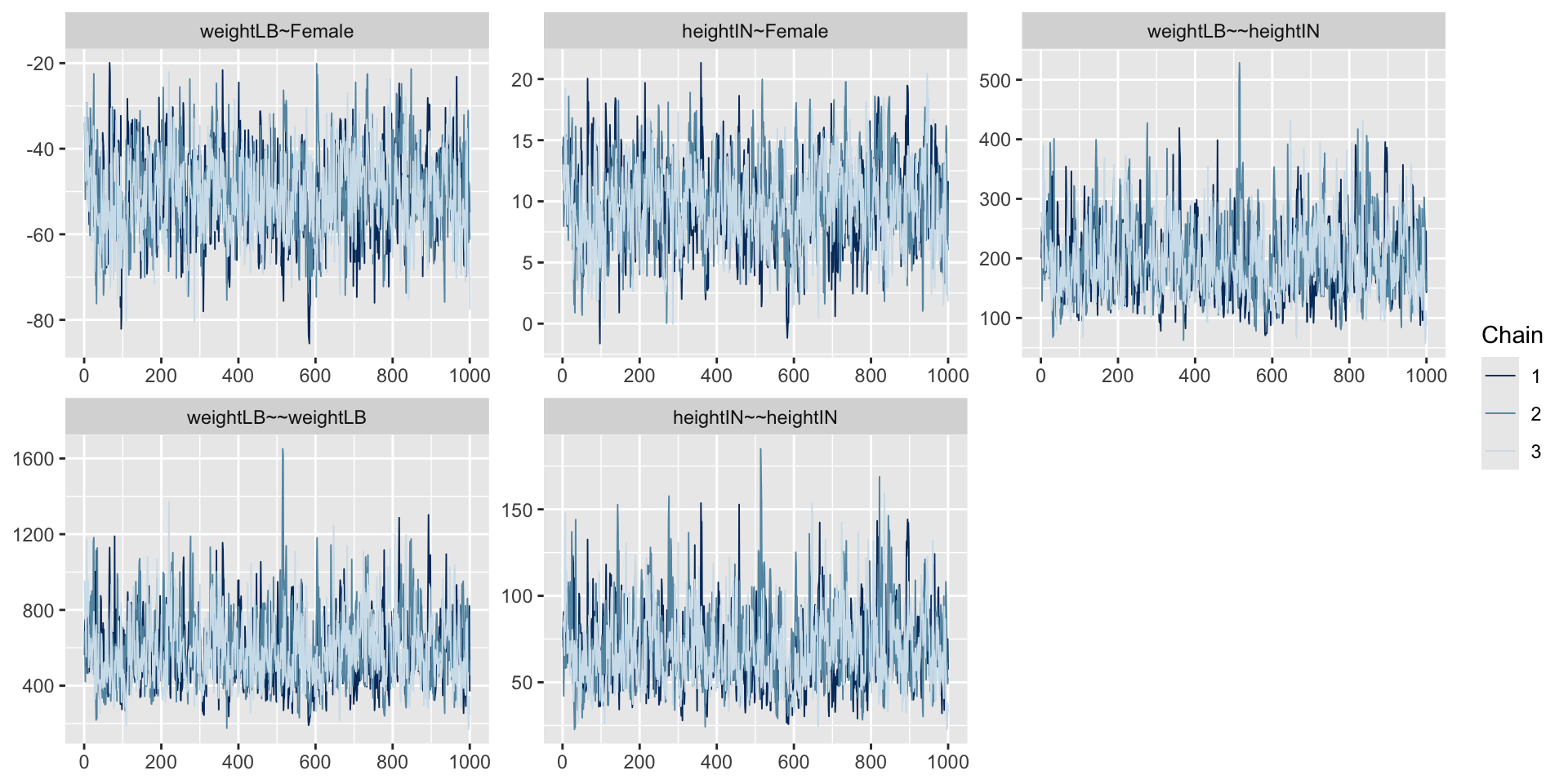
Trace Plots of Parameters
Posterior Distribution of coefficient
MLE results
lhs op rhs est se z pvalue ci.lower ci.upper
1 weightLB ~ Female -105.00 7.265 -14.453 0.000 -119.239 -90.761
2 heightIN ~ Female -8.60 2.612 -3.293 0.001 -13.718 -3.482
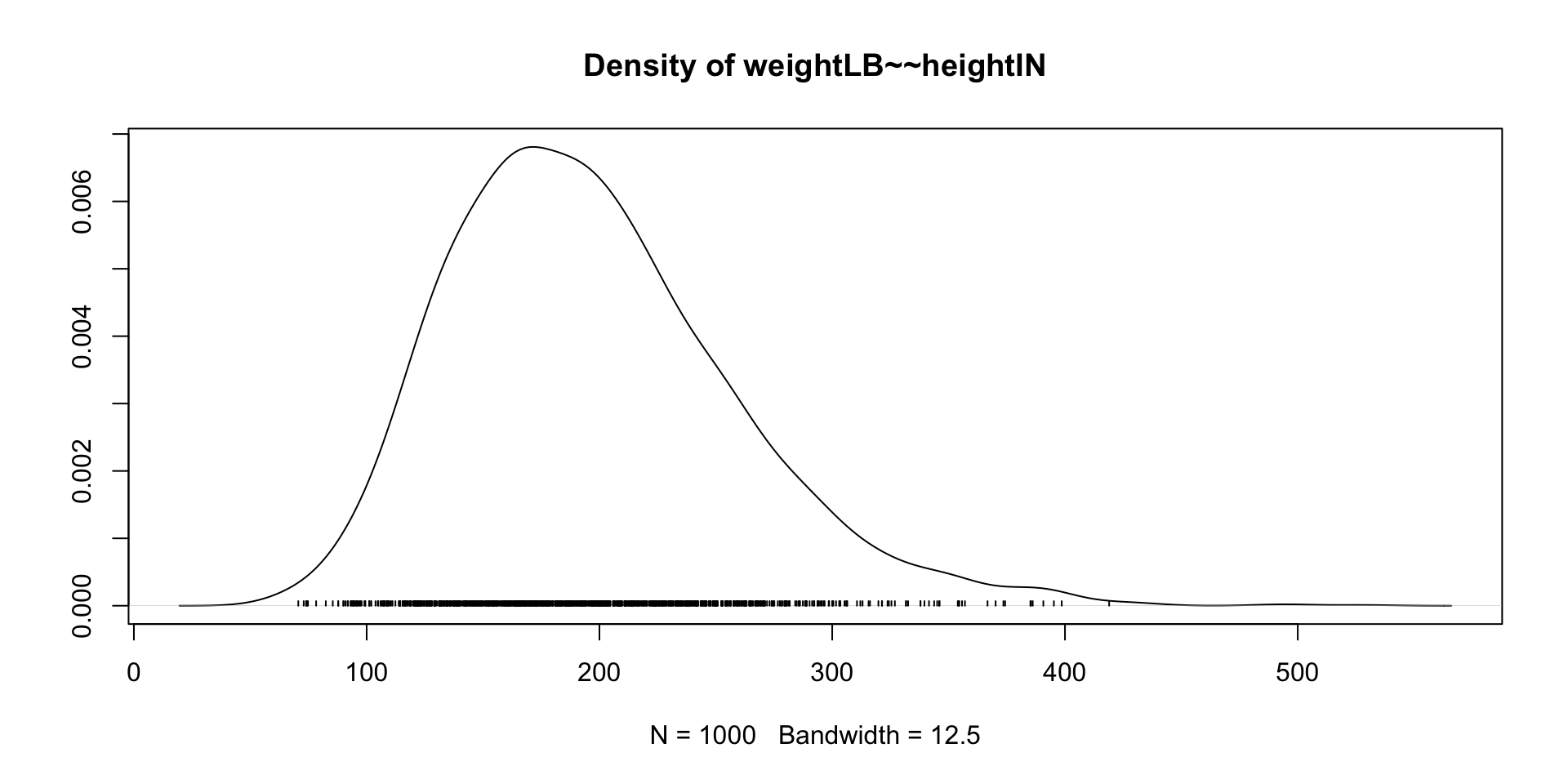
3 weightLB ~~ heightIN 92.34 29.602 3.119 0.002 34.322 150.358
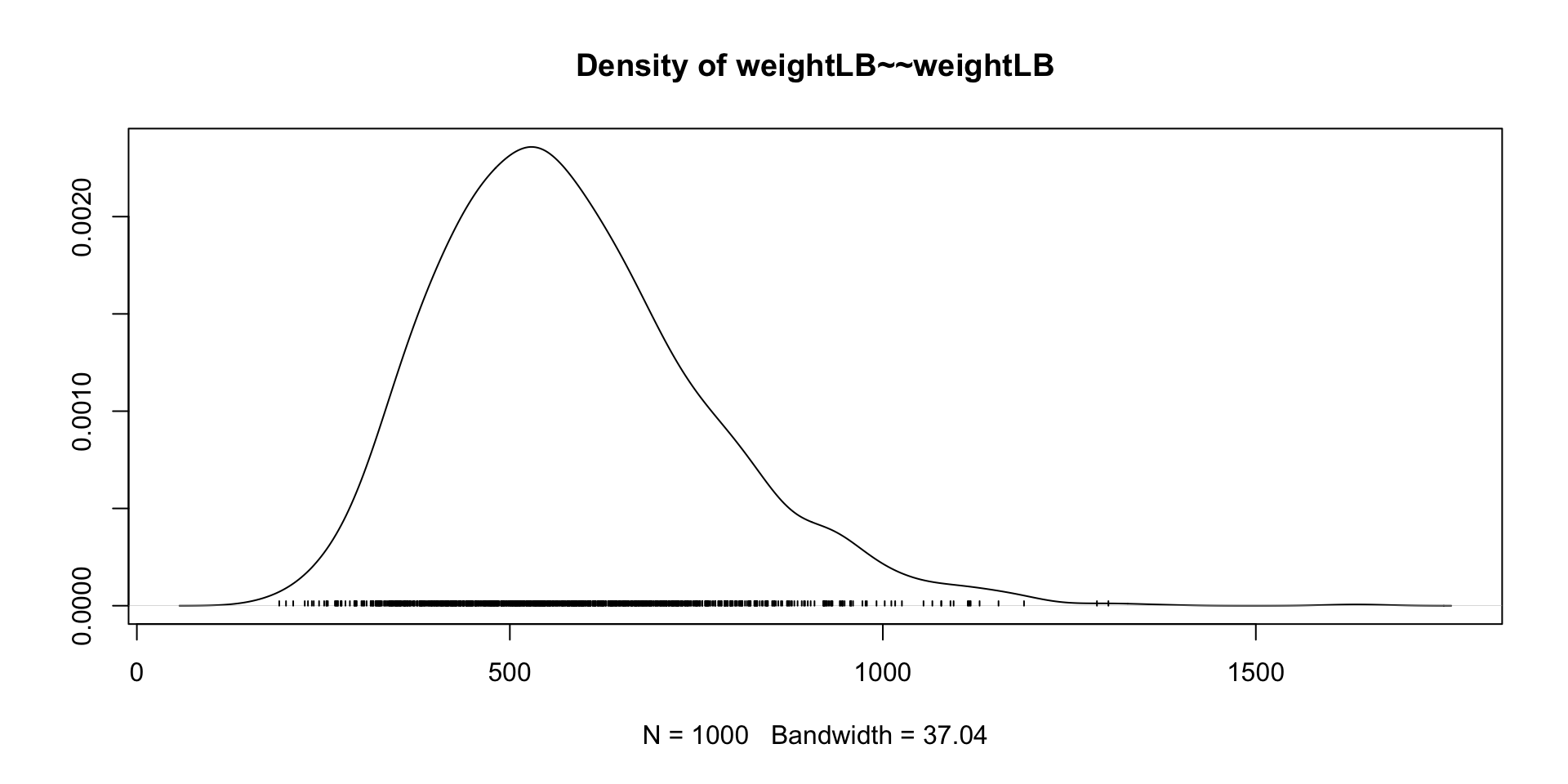
4 weightLB ~~ weightLB 263.89 83.449 3.162 0.002 100.332 427.448
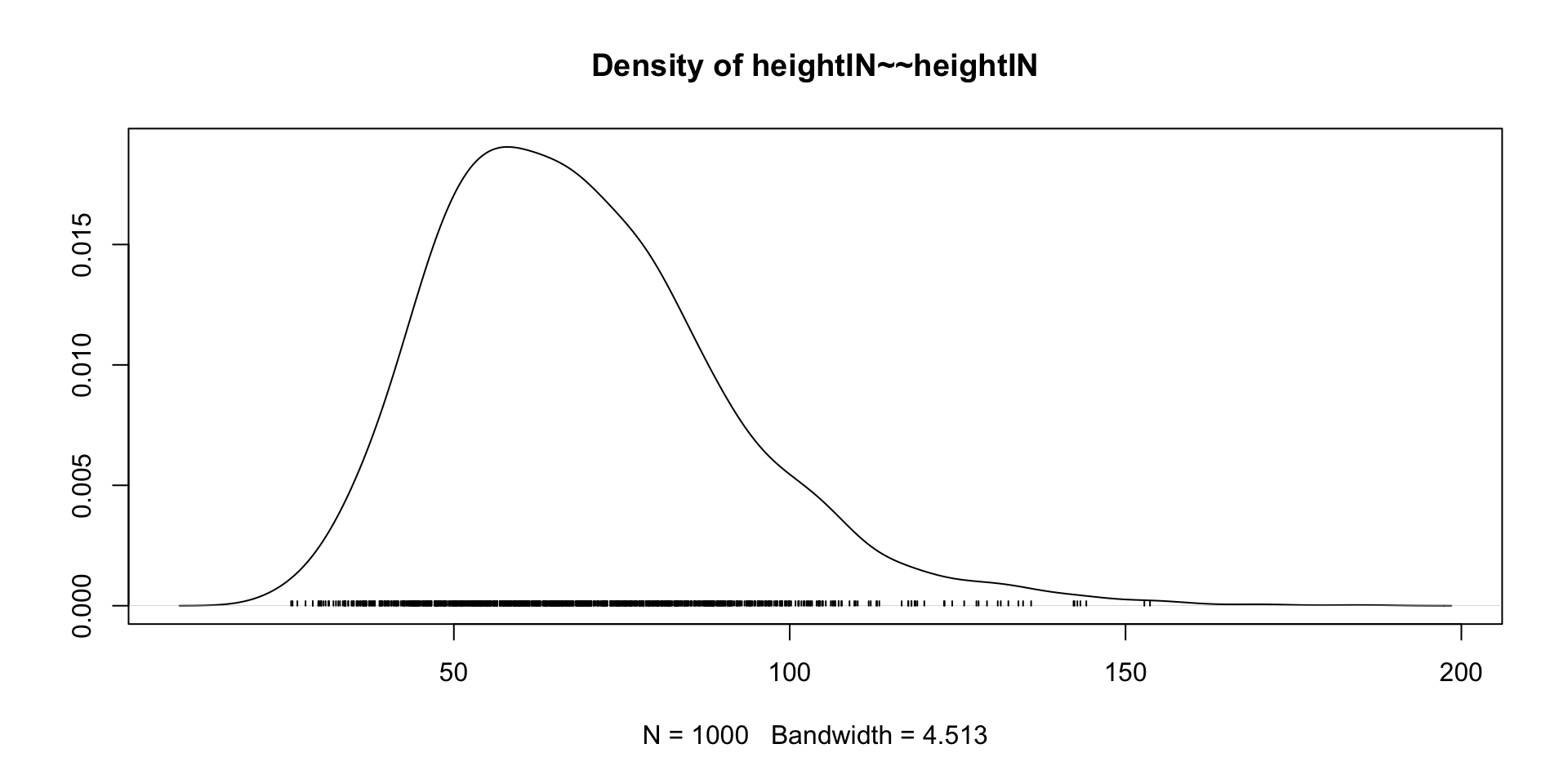
5 heightIN ~~ heightIN 34.10 10.783 3.162 0.002 12.965 55.235
6 Female ~~ Female 0.25 0.000 NA NA 0.250 0.250MCMC results
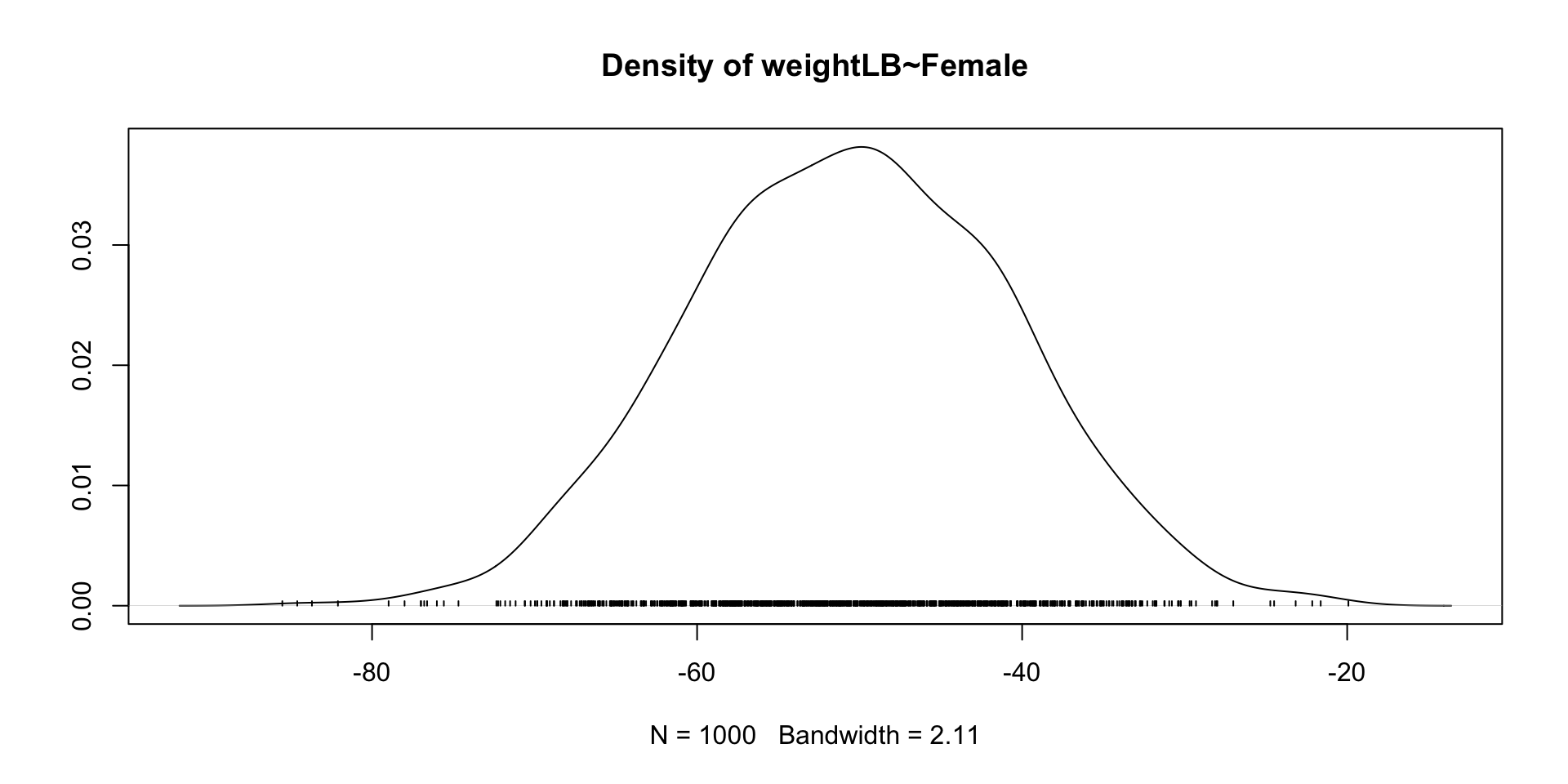
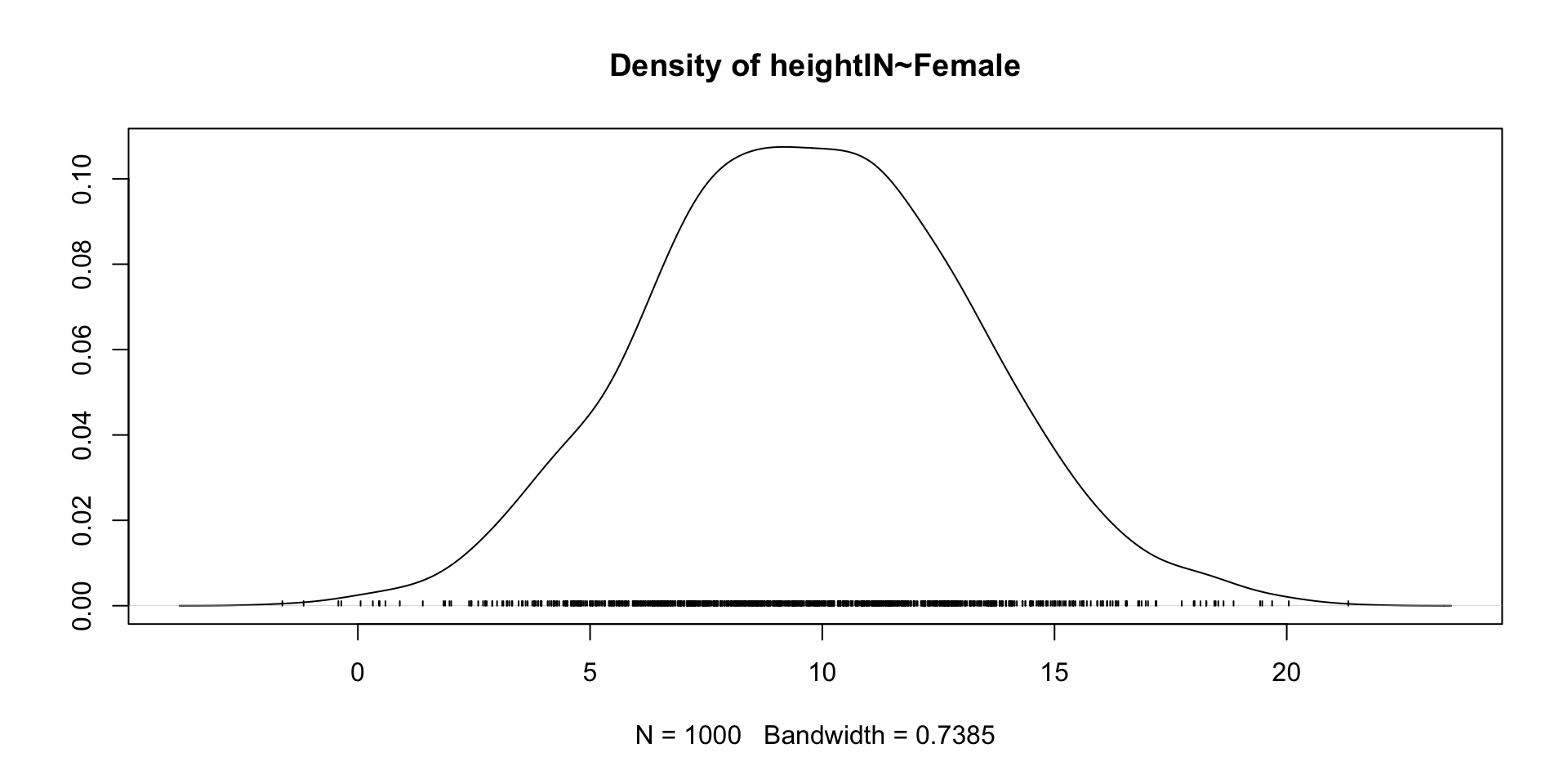
Wrapping up
Today is a quick introduction to Bayesian Concept
- Bayes’ Theorem: Fundamental theorem of Bayesian Inference
- Prior distribution: What we know about the parameter before seeing the data
- hyperparameter: parameter(s) of the prior distribution(s)
- Uninformative prior: Prior distribution that does not convey any information about the parameter
- Informative prior: Prior distribution that conveys information about the parameter
- Conjugate prior: Prior distribution that makes the posterior distribution the same family as the prior distribution
- Likelihood: What the data tell us about the parameter
- Likelihood function: Probability of the data given the parameter
- Likelihood principle: All the information about the data is contained in the likelihood function
- Likelihood is a sort of “scientific judgment” on the generation process of the data
- Posterior distribution: What we know about the parameter after seeing the data
![]()