Class Outline
- Brief introduction to the different types of experimental design
- Validity
1.1 Types of Experimental Design
There are three basic types of experimental research designs:
Pre-experimental designs: no control group
True experimental designs: control group with random assignment
Quasi-experimental designs: control group but no random assignment; assignment is often based on pre-existing criteria.
- e.g., Group A: high-performance vs. Group B: low-performance
A true experimental design also has different sub-types: post-test only, pre-post, four-group, factorial design, block design
They are characterized by the methods of random assignment and random selection.
These designs help control for extraneous variables.
1.2 Sub-types of true experimental designs
1.2.1 Post-test Only Design
- Features: control vs. treatment, randomly assigned
| Group | Treatment | Post-test |
|---|---|---|
| 1 (treatment) | X | O |
| 2 (control) | O |
1.2.2 Pre-Post-test Only Design
- Features: control vs. treatment, randomly assigned
A researcher wants to determine if a new reading intervention program improves reading comprehension in second-grade students.
- Group 1 (Treatment Group): Students are given a pre-test to assess their initial reading comprehension. They then participate in the new reading program for six weeks. After the program, they are given a post-test.
- Group 2 (Control Group): Students are also given the same pre-test. However, they continue with their standard reading curriculum. After six weeks, they are given the same post-test.
By comparing the pre-test and post-test scores between the two groups, the researcher can determine if the intervention program caused a significant improvement in reading comprehension compared to the standard curriculum.
1.2.3 Solomon Four-Group Design
- Features: two treatment groups and two control groups. Only two groups are pre-tested.
- One pre-tested group and one un-pretested group receive the treatment.
- All four groups will receive the post-test.
- Use this design when it is suspected that taking a test more than once may cause earlier tests to affect later tests.
- The design is a combination of the pretest-posttest and posttest-only designs. It allows the researcher to control for the potential effects of a pre-test. The effect of the pre-test is known as a “testing threat” to internal validity — the pre-test itself might influence the post-test outcome.
- By using four groups, researchers can isolate the effect of the treatment from the effect of the pre-test and any interaction between the two. It helps to increase the external validity of the findings.
Imagine a study evaluating the effectiveness of a new diversity and inclusion training program in a company. Researchers are concerned that a pre-test measuring employees’ attitudes might make them more aware of the issues and thus influence their responses on the post-test, regardless of the quality of the training.
- Group 1 (Pre-test, Training, Post-test): Measures the effect of the training on employees who were sensitized by the pre-test.
- Group 2 (No Pre-test, Training, Post-test): Measures the effect of the training without pre-test sensitization.
- Group 3 (Pre-test, No Training, Post-test): Measures the effect of the pre-test itself. Did just taking the survey change their attitudes?
- Group 4 (No Pre-test, No Training, Post-test): Acts as the baseline control group.
By comparing the post-test results across these four groups, the researchers can determine the true effect of the training program, the effect of being pre-tested, and whether the pre-test made employees more or less receptive to the training.
| Group | Treatment | Pre-test | Post-test |
|---|---|---|---|
| 1 | X | O | O |
| 2 | X | O | |
| 3 | O | O | |
| 4 | O |
1.2.4 Factorial Design
The researcher manipulates two or more independent variables (factors) simultaneously to observe their effects on the dependent variable.
Features:
- It involves two or more independent variables (or factors).
- Each factor has two or more levels (conditions).
- It allows researchers to examine the main effects of each factor independently.
- Crucially, it also allows for the examination of interaction effects between factors, meaning the effect of one factor may depend on the level of another.
- This design allows for the testing of two or more hypotheses in a single project.
A study investigating the factors that cause workplace stress seeks to examine the effect of various combinations of background noise and interruptions on employee stress levels.
- Factor 1 (Independent Variable): Background Noise, with three levels (Low, Medium, High).
- Factor 2 (Independent Variable): Interruption Rate, with two levels (Low, High).
- Dependent Variable: Stress, measured by scores on a standardized stress test.
This is a 3x2 factorial design, which creates 3 * 2 = 6 different experimental conditions or groups:
- Low Noise / Low Interruptions
- Low Noise / High Interruptions
- Medium Noise / Low Interruptions
- Medium Noise / High Interruptions
- High Noise / Low Interruptions
- High Noise / High Interruptions
Participants would be randomly assigned to one of these six conditions. This design allows researchers to answer three key questions:
What is the main effect of background noise on stress? (i.e., does noise level, in general, affect stress?)
What is the main effect of interruptions on stress? (i.e., does the interruption rate, in general, affect stress?)
What is the interaction effect between noise and interruptions? (i.e., does the effect of interruptions on stress depend on the level of background noise? For example, perhaps high interruptions are only stressful when combined with high noise.)
1.2.5 Randomized Block Design
This design is a technique for dealing with nuisance factors — variables that are not of primary interest but may nonetheless influence the outcome variable.
Features:
Purpose: To minimize the effect of a single, known nuisance variable on the outcome.
Blocking: Participants are first divided into homogeneous groups or “blocks” based on the nuisance variable (e.g., age, gender, IQ).
Randomization: Within each block, participants are randomly assigned to the treatment or control conditions.
Benefit: This design reduces variability within each block, making it easier to detect the true effect of the treatment.
Suppose we want to conduct a post-test-only design and recognize that our sample contains several homogeneous subgroups.
In a study of college students, we might expect students to be relatively homogeneous with respect to academic year.
- We can block the sample into four groups: freshman, sophomore, junior, and senior.
- We will probably get more powerful estimates of the treatment effect within each block.
- Within each of our four blocks, we would implement the simple post-test-only randomized experiment.
| Block | Group | Treatment | Post-test |
|---|---|---|---|
| F. | 1 | X | O |
| F. | 2 | O | |
| Sop. | 1 | X | O |
| Sop. | 2 | O | |
| Ju. | 1 | X | O |
| Ju. | 2 | O | |
| Sen. | 1 | X | O |
| Sen. | 2 | O |
1.2.6 Repeated Measures Design
- Each group member in an experiment is tested for multiple conditions over time or under different conditions.
- An ordinary repeated measures design is one where patients are assigned a single treatment, and the results are measured over time (e.g., at 1, 4, and 8 weeks).
- A crossover design is where patients are assigned all treatments, and the results are measured over time.
- The most common crossover design is “two-period, two-treatment.” Participants are randomly assigned to receive either A then B, or B then A.
A study aims to test the effectiveness of a new medication for lowering blood pressure. Instead of using different groups for treatment and control, researchers recruit one group of patients.
- Baseline: The blood pressure of each patient is measured before the treatment begins.
- Treatment: All patients take the new medication for 30 days.
- Follow-up: Their blood pressure is measured again at 15 days and 30 days into the treatment.
Because the same participants are measured at multiple points in time, this is a repeated measures design. The key advantage is that it controls for individual differences between participants, making it a very powerful way to detect the effect of the treatment.
1.3 Wrap-up: Comparing Experimental Designs
Choosing the right experimental design depends on your research question, available resources, and the threats to validity you most need to control.
| Design | Pros | Cons | Use When | Example |
|---|---|---|---|---|
| Post-test Only | Simple; no pre-test sensitization; low cost | No baseline; relies entirely on randomization for equivalence | Random assignment is ensured and pre-testing would sensitize participants | Randomly assigning classrooms to a new teaching method and comparing end-of-unit scores |
| Pre-Post-test | Establishes baseline; documents individual change | Pre-test may sensitize participants; requires more time and resources | Baseline measurement is essential and sensitization is not a major concern | Measuring student anxiety before and after an 8-week mindfulness program |
| Solomon Four-Group | Controls for both pre-test sensitization and treatment effects | Requires four groups; expensive; complex to implement and analyze | Rigorous control of testing threats is needed and sufficient participants are available | Testing a bias-awareness training where the pre-test survey itself could trigger attitude change |
| Factorial | Tests multiple IVs and their interactions efficiently in one study | Larger samples needed; complex analysis; interactions can be hard to interpret | Two or more IVs may interact; interested in how the effect of one variable depends on another | Studying how teaching method (lecture vs. inquiry) and class size (small vs. large) jointly affect achievement |
| Randomized Block | Reduces error variance by controlling a known nuisance variable; increases power | Nuisance variable must be identified before data collection | A known covariate (e.g., SES, grade level, gender) is expected to substantially influence the outcome | Blocking by prior GPA before randomly assigning students to a study-skills intervention |
| Repeated Measures | Each participant is their own control; fewer participants needed; high statistical power | Carryover, order, and fatigue effects; attrition over time | Tracking within-person change over time, or when sample size is limited and individual differences are large | Measuring the same students’ reading fluency at four time points across a school year |
Before finalizing your design, ask yourself:
- Can I randomly assign participants? → If yes, a true experimental design is viable. If no, consider a quasi-experimental design.
- Do I need a baseline measure? → If yes, use a Pre-Post-test or Solomon design.
- Will the pre-test sensitize participants? → If yes, consider a Post-test Only or Solomon Four-Group design.
- Do I have more than one independent variable? → If yes, consider a Factorial design.
- Is there a known nuisance variable that could mask the treatment effect? → If yes, use a Randomized Block design.
- Is my sample small, or do I need to track change within individuals over time? → If yes, consider a Repeated Measures design.
1.4 Exercise: Choose the Right Design
For each scenario below, select the experimental design that best fits the research purpose. Be prepared to explain your reasoning.
Question 1
A researcher wants to evaluate whether a new phonics-based reading program improves literacy in first graders. She randomly assigns 40 students to either the new program or the standard curriculum. Because she worries that administering a reading pre-test might prime students to pay special attention to phonics — independently of the program — she only collects reading scores at the end of the 6-week period.
Which experimental design is she using?
- Pre-Post-test Design
- Solomon Four-Group Design
- Post-test Only Design
- Repeated Measures Design
Answer
C. Post-test Only Design — The researcher uses random assignment but deliberately omits a pre-test to prevent sensitization. With only a post-test measurement and no baseline, this is a classic post-test only design. The pre-test concern she describes is precisely the “testing threat” that motivates avoiding a pre-test.Question 2
A school counselor evaluates whether a mindfulness-based stress reduction program decreases test anxiety in 9th graders. She measures each student’s anxiety at the start of the semester, delivers the 8-week program, and then measures anxiety again at the end. Her primary goal is to document how much each individual student’s anxiety changed over the course of the program.
Which design best fits her study?
- Post-test Only Design
- Randomized Block Design
- Pre-Post-test Design
- Factorial Design
Answer
C. Pre-Post-test Design — The counselor measures anxiety before and after the intervention and is primarily interested in documenting change within each student. This is the defining feature of a pre-post-test design. Both groups (treatment and control, if present) receive the same pre-test and post-test.Question 3
A researcher is testing whether a new anti-bullying curriculum changes middle schoolers’ attitudes toward bullying. She is concerned that completing a pre-test survey about bullying might itself make students more sensitive to the issue — independent of the curriculum. She has 200 participants available and wants to isolate the true effect of the curriculum from any pre-test sensitization.
Which design should she use?
- Post-test Only Design
- Repeated Measures Design
- Randomized Block Design
- Solomon Four-Group Design
Answer
D. Solomon Four-Group Design — The Solomon Four-Group design is specifically developed to address pre-test sensitization. By including both pre-tested and non-pre-tested groups within both treatment and control conditions, it allows the researcher to estimate the effect of the curriculum separately from any effect caused by the pre-test itself.Question 4
An educational psychologist hypothesizes that the effectiveness of a growth mindset intervention depends on both the student’s grade level (middle school vs. high school) and the delivery format (in-person vs. online). She wants to examine not only whether each factor independently affects outcomes, but also whether the two factors interact with each other.
Which design is most appropriate?
- Repeated Measures Design
- Factorial Design
- Pre-Post-test Design
- Randomized Block Design
Answer
B. Factorial Design — A factorial design is used whenever a researcher manipulates two or more independent variables and is interested in their interaction. Here, grade level (2 levels) × delivery format (2 levels) creates a 2×2 factorial design that can simultaneously test main effects and the interaction effect.Question 5
A developmental psychologist wants to track how children’s executive function skills develop across one academic year. She measures the same 25 children on an executive function task at the beginning, middle, and end of the year. Her sample is small because the assessment is expensive and time-consuming, and she wants to maximize statistical power by using each child as their own control.
Which design does her study employ?
- Post-test Only Design
- Solomon Four-Group Design
- Randomized Block Design
- Repeated Measures Design
Answer
D. Repeated Measures Design — The same participants are measured at multiple time points, making this a repeated measures design. This approach controls for individual differences (each child is their own baseline), maximizes power with a small sample, and is the natural choice when the goal is to track within-person change over time.2 Validity
2.1 Why it matters
When we review experiments with a critical view, one question to ask is “Is this study valid?”
Validity is the foundation of trustworthy research. It ensures that the conclusions we draw are accurate and meaningful. Without it, we might be measuring the wrong thing, mistaking correlation for causation, or finding results that don’t apply to the real world.
- Internal Validity: Imagine a study finds that a new teaching method improves test scores. But what if the study took place over a whole year? The students might have improved simply because they got older and more mature, not because of the new method. If so, the study lacks internal validity.
- External Validity: A study finds that a new productivity app works great for a group of college students. But would it work for retired adults? Or for doctors in a busy hospital? If the results don’t generalize to other groups and settings, the study lacks external validity.
- Construct Validity: A researcher creates a survey to measure “happiness.” But if the questions are all about how much money someone makes, is it really measuring happiness, or is it measuring wealth? If the tool doesn’t accurately measure the theoretical concept, the study lacks construct validity.
2.2 Conceptions of Validity
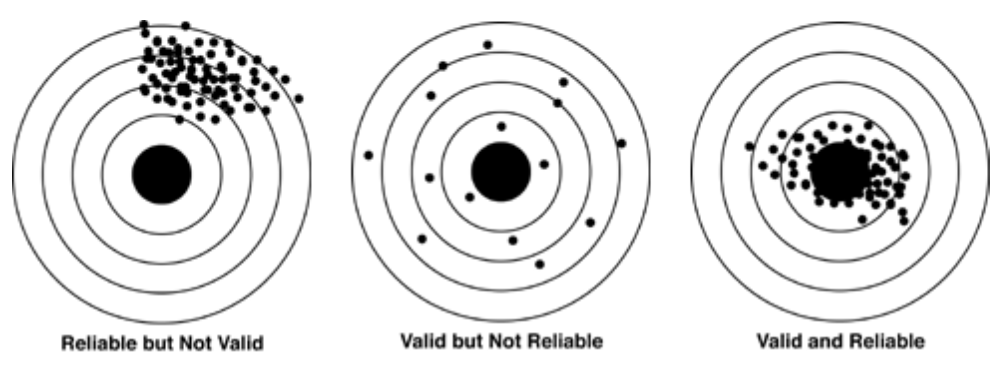
- What is Validity? At its core, validity refers to the degree of truth and accuracy of the inferences or conclusions drawn from a study. It’s a judgment about how well the evidence supports the claims being made.
- Importantly, validity is never absolute; it’s a matter of degree. We talk about “strong” or “weak” validity, not “perfect” validity.
- Validity is About Inferences, Not Methods: This distinction is crucial.
- A research method (like a survey or an experiment) is just a tool. The validity lies in how that tool is used and how the results are interpreted.
- Think of it like this: Owning a professional-grade oven (a strong research design) doesn’t guarantee a perfect cake (a valid conclusion). If you use the wrong ingredients or misread the recipe (poor implementation or analysis), the conclusion can be invalid.
- Therefore, simply using a powerful design does not guarantee a valid inference.
- No Design is Immune to Threats: Even the “gold standard” of research, the randomized experiment cannot guarantee a valid causal inference on its own. It can be undermined or “broken” by issues such as:
2.3 Randomized Experiments
Randomized experiments are often called the “gold standard” of research design, particularly for establishing internal validity, because they are the most effective way to establish a cause-and-effect relationship between a treatment and an outcome.
By randomly assigning participants to groups, the experimenter creates two or more groups that are statistically equivalent, on average, before the treatment is applied. This process minimizes selection bias and ensures that other potential causes (e.g., age, motivation, prior knowledge) are distributed equally across the groups.
Therefore, if a difference is observed between the groups after the treatment, the researcher can be much more confident that the difference was caused by the treatment and not by some other pre-existing factor.
Randomized experiments allow researchers to scientifically measure the impact of an intervention on a particular outcome of interest (e.g., the effect of intervention methods on performance).
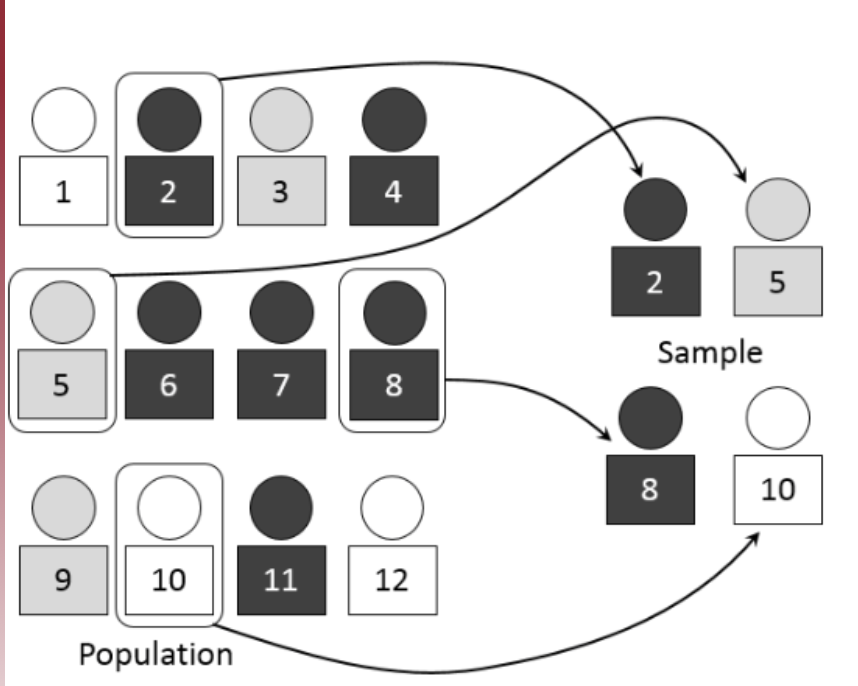
The key to a randomized experimental research design is the random assignment of study subjects:
- For example, randomly assign individual people, classrooms, or some other group into a) treatment or b) control groups.
Randomization has a very specific meaning:
- It does not mean haphazardly or casually selecting some participants and not others.
Randomization in this context means: care is taken to ensure that no pattern exists between the assignment of subjects into groups and any characteristics of those subjects.
- Ex: Not all females over 30 are in the exercise group, females 18-30 in the diet group, and males in the control group.
- Every subject is as likely as any other to be assigned to the treatment (or control) group.
2.3.1 Why Randomized Assignment
- Researchers demand randomization for several reasons:
- First, participants in various groups should not differ in any systematic way.
- In an experiment, if treatment groups are systematically different, the trial results will be biased.
- Suppose that participants are assigned to control and treatment groups in a study examining the efficacy of a walking intervention. If a greater proportion of older adults is assigned to the treatment group, then the outcome of the walking intervention may be influenced by this imbalance.
- The effects of the treatment would be indistinguishable from the influence of the imbalance of covariates (e.g., age), thereby requiring the researcher to control for the covariates in the analysis to obtain an unbiased result.
- In an experiment, if treatment groups are systematically different, the trial results will be biased.
2.3.2 Why Randomized Assignment (Cont.)
- Second, proper randomization ensures that there is no a priori knowledge of group assignment.
- That is, researchers, participants, and others should not know to which group the participant will be assigned.
- Knowledge of group assignment creates a layer of potential selection bias that may taint the data.
- Trials with inadequate or unclear randomization tended to overestimate treatment effects up to 40% compared with those that used proper randomization!
- The outcome of the trial can also be negatively influenced by this inadequate randomization.
- That is, researchers, participants, and others should not know to which group the participant will be assigned.
2.4 Types of Validity
- Statistical Validity
- Internal Validity
- Construct Validity
- External Validity
2.5 Statistical Validity
- Statistical (Conclusion) Validity
- Question: “Was the original statistical inference correct?”
- Statistical validity concerns whether the investigators used the proper type of statistical test to analyze the data, and whether they arrived at the correct conclusion about whether a relationship exists between the variables.
- It is not concerned with the causal relationship between variables — only whether there is any relationship, causal or not.
2.5.1 Statistical Validity (Cont.)
Concern:
- The primary concern is using the appropriate statistical tests to analyze the data.
Threats:
- Liberal biases: Researchers are overly optimistic about the existence of a relationship or exaggerate its strength.
- Conservative biases: Researchers are overly pessimistic about the absence of a relationship or underestimate its strength.
- Low power: The probability of a Type II error is unacceptably high.
Causes of Threats:
- Small sample sizes, violation of statistical assumptions, too many repeated experimental trials, use of biased estimates of effects, increased error from irrelevant, unreliable, or poorly constructed measures, high variability due to participant diversity, etc.
2.5.2 Addressing Threats to Statistical Validity
- Different statistical inference methods have different tools to address validity:
- Effect size
- p-value adjustments for multiple comparisons
- Controlling for Type I error
- Including control variables (e.g., gender, race, age)
- Power analysis (to ensure an appropriate number of participants are recruited and tested)
Example 1 — Underpowered study (Low Power)
A school counselor wants to test whether a 4-week mindfulness program reduces math anxiety in middle school students. She recruits only 10 students per group (treatment vs. control) and runs an independent-samples t-test. The program actually has a small-to-medium effect, but with only 20 total participants the study has roughly 30% power — far below the recommended 80%. The result is non-significant, and she incorrectly concludes that mindfulness has no effect. This is a Type II error driven by low statistical power.
Fix: A power analysis before data collection would have revealed that approximately 52 students per group are needed to detect a medium effect (d = 0.5) at 80% power.
Example 2 — Inflated Type I error from multiple comparisons
A researcher studies the effect of a new reading intervention on five outcome measures: reading fluency, comprehension, vocabulary, writing quality, and attendance. She runs a separate t-test for each outcome without adjusting the alpha level. With five tests at \alpha = .05, the probability of at least one false positive exceeds 22%. She reports a significant effect on vocabulary and claims the intervention works — but this finding may be a chance result.
Fix: Apply a Bonferroni correction (use \alpha = .05/5 = .01 per test) or use a multivariate test (MANOVA) to test all outcomes simultaneously.
Example 3 — Violated statistical assumption
A psychology graduate student examines whether students’ self-reported stress levels differ across three academic programs (Education, Psychology, Engineering) using a one-way ANOVA. However, she collects data from only 5 students per group and never checks for normality. With such small samples and an ordinal Likert scale, the normality assumption is likely violated, making the F-test results untrustworthy.
Fix: Use a non-parametric alternative (e.g., Kruskal-Wallis test) when sample sizes are small and distributional assumptions cannot be verified.
2.6 Internal Validity
- Internal Validity:
- Question: “Is there a causal relationship between variable X and variable Y, regardless of what X and Y are theoretically supposed to represent?”
- Internal validity is achieved when it can be concluded that there is a causal relationship between the variables being studied — that the treatment, and not some other factor, caused the observed change.
- A danger is that changes might be caused by other factors.
- Threats to internal validity:
- Maturation, history, instrumentation, regression, selection, etc.
- Diffusion or imitation of treatments, compensatory equalization of treatments, compensatory rivalry by people receiving less desirable treatments (John Henry effect), and resentful demoralization of respondents receiving less desirable treatments.
Resentful demoralization is a threat to internal validity that occurs when participants in a control group become discouraged or resentful because they are not receiving the treatment.
As a result, they may:
- Try less hard
- Perform worse than they normally would
- Lose motivation
- Withdraw effort
This artificially inflates the difference between the treatment and control groups — making the treatment look more effective than it actually is.
2.6.0.1 Why it threatens internal validity
Internal validity is about whether the treatment truly caused the outcome.
With resentful demoralization:
- The difference between groups may be caused partly by control group discouragement, not just the treatment itself.
- So the causal conclusion becomes questionable.
2.6.0.2 Example
Imagine a study testing a new study-skills program:
- Treatment group: gets special coaching and extra resources
- Control group: gets nothing
If control participants realize they are missing out, they may feel:
“Why bother trying? They’re getting the help anyway.”
Their performance drops — not because the treatment works so well, but because the control group became demoralized.
Imagine a study measures the effectiveness of a 3-month public health campaign designed to increase recycling.
- Pre-test: Researchers measure recycling rates in a city.
- Treatment: The public health campaign runs for 3 months.
- Post-test: Researchers measure recycling rates again and find a significant increase.
The conclusion seems to be that the campaign worked. However, during that same 3-month period, a very popular celebrity independently launched their own high-profile “Go Green” initiative. Now, it’s impossible to know if the increase in recycling was due to the health campaign or the celebrity’s influence. This external event is a history threat that compromises the study’s internal validity.
Example 1 — Maturation threat
A researcher implements a 9-month phonics intervention for first-grade students and measures reading fluency at the start and end of the school year. Reading scores improve significantly. However, first-graders naturally develop reading skills over the course of a year through brain maturation and general classroom instruction. Without a control group, it is impossible to determine how much of the gain is due to the intervention versus normal developmental growth.
Example 2 — Selection bias
A school district offers an optional after-school tutoring program and later compares the final exam scores of students who attended with those who did not. Attendees score higher on average. However, students who voluntarily joined the program were likely already more motivated, more engaged, or had more parental support. The observed difference may reflect pre-existing differences between groups rather than the effect of tutoring itself.
Example 3 — Regression to the mean
A district identifies the 50 students who scored in the bottom 10% on a standardized math test and enrolls them in an intensive remediation program. At the end of the semester, their average score rises noticeably. But scores at the extreme low end naturally tend to move upward on retesting due to statistical regression to the mean — even without any intervention. Attributing all the improvement to the program would be an internal validity error.
Example 4 — Instrumentation threat
A study measures student anxiety using a validated 20-item scale at pre-test, but the research team switches to a shorter 10-item scale at post-test to save time. Any observed change in scores may partly or entirely reflect the change in measurement instrument rather than a true change in anxiety levels.
2.7 External Validity
- External Validity
- Question: “Can the finding be generalized across populations, settings, or time?”
- External validity is the degree to which the results of a study can be generalized beyond the specific sample, setting, and time period of the original research.
- A primary concern is the heterogeneity and representativeness of the study sample.
- e.g., In many psychology experiments, the participants are all undergraduate students and come to a classroom or laboratory to fill out a series of paper-and-pencil questionnaires or to perform a carefully designed computerized task.
Consider, for example, an experiment in which researcher Barbara Fredrickson and her colleagues had undergraduate students come to a laboratory on campus and complete a math test while wearing a swimsuit (Fredrickson et al., 1998). At first, this manipulation might seem silly. When will undergraduate students ever have to complete math tests in their swimsuits outside of this experiment?
Assumption: “This self-objectification is hypothesized to (a) produce body shame, which in turn leads to restrained eating, and (b) consume attention resources, which is manifested in diminished mental performance.”
“Self-objectification increased body shame, which in turn predicted restrained eating.”
In one such experiment, Robert Cialdini and his colleagues studied whether hotel guests chose to reuse their towels for a second day as opposed to having them washed as a way of conserving water and energy (Cialdini, 2005).
- These researchers manipulated the message on a card left in a large sample of hotel rooms.
- One version of the message emphasized showing respect for the environment.
- Another emphasized that the hotel would donate a portion of their savings to an environmental cause.
- A third emphasized that most hotel guests choose to reuse their towels.
- Results: Guests who received the message that “most hotel guests choose to reuse their towels (Message 3)” reused their own towels substantially more often than guests receiving either of the other two messages.
- Guests were randomly selected, hotels were randomly chosen, and a large sample of hotel rooms was used.
Threats to External Validity:
- Interaction of Selection and Treatment: Does the program’s impact apply only to this particular group, or is it also applicable to other individuals with different characteristics?
- Interaction of Testing and Treatment: If your design included a pre-test, would your results be the same if implemented without one?
- Interaction of Setting and Treatment: How much are your results impacted by the program’s setting, and could you apply this program within a different setting and see similar results?
- Interaction of History and Treatment: A simplified way to think about this is to ask how “timeless” the program is. Could you get the same results in a future setting, or did something specific to this time point (e.g., a major event) influence the impact?
- Multiple Treatment Threats: The program may exist in an ecosystem that includes other programs. Can the results be generalized to other settings without the same program-filled environment?
As a general rule, studies are higher in external validity when the participants and the situation studied are similar to those that the researchers want to generalize to and that participants encounter every day, often described as mundane realism.
The best approach to minimize this threat is to use a heterogeneous group of settings, people, and times.
Example 1 — Interaction of selection and treatment (WEIRD samples)
A researcher tests a growth mindset intervention and finds it significantly raises academic persistence among undergraduate psychology students at a large research university. She concludes the intervention should be adopted nationwide. However, her sample is almost entirely 18–22-year-old, college-educated, and self-selected into a psychology course. Whether the same intervention works for elementary school students, adult learners, or students in under-resourced rural schools remains unknown. The finding may not generalize beyond the original sample.
Example 2 — Interaction of setting and treatment
A counseling psychologist develops a trauma-informed social-emotional learning (SEL) curriculum and tests it in a well-funded suburban school with small class sizes, trained counselors on staff, and strong administrator support. Results are impressive. However, when the same curriculum is adopted by an urban district with large class sizes, few support staff, and limited professional development time, outcomes are far weaker. The original results did not generalize to a different setting.
Example 3 — Interaction of history and treatment
A study evaluating the effect of online collaborative learning on student engagement was conducted in spring 2020, when schools abruptly shifted to remote instruction during the COVID-19 pandemic. Students and teachers were highly motivated to make technology-based collaboration work. A researcher who concludes “online collaboration improves engagement” and tries to replicate the finding in 2025 under normal in-person conditions may get very different results — the extraordinary historical context was a key driver of the original outcome.
Example 4 — Interaction of testing and treatment
Researchers administer a detailed pre-test on attitudes toward diversity before implementing a multicultural education program. Post-test scores show significantly more positive attitudes. However, the pre-test itself likely sensitized students to diversity issues and primed them to think about the topic before the program began — an effect that would not occur if the program were implemented in a school without a pre-test. The findings may not generalize to real-world program delivery without the pre-test.
2.8 Construct Validity
- This is perhaps the broadest or most diffuse concept among the four validity types.
- “Do your measured math scores represent MATH?”
- DEFINITION: The degree to which a test or instrument is capable of measuring a concept, trait, or other theoretical entity.
- “Do the theoretical constructs of cause and effect accurately represent the real-world situations they are intended to model?”
- It concerns the general process of translating any theoretical construct into an operationalization.
- For example, if a researcher develops a new questionnaire to evaluate respondents’ levels of aggression, the construct validity of the instrument would be the extent to which it actually assesses aggression as opposed to assertiveness, social dominance, and so forth.
- There are subtypes of construct validity:
- Convergent validity (=congruent validity): The extent to which responses on a test exhibit a strong relationship with responses on conceptually similar tests or instruments.
- Discriminant validity (=divergent validity): The degree to which a test diverges from (i.e., does not correlate with) another measure whose underlying construct is conceptually unrelated to it.
- Face validity, content validity, predictive validity, concurrent validity, etc.
Example 1 — Measuring “critical thinking” or measuring reading speed?
A school district develops a new “critical thinking” assessment for 4th graders that consists of complex, lengthy reading passages followed by inferential questions. Students who score low are labeled as weak critical thinkers and placed in an intervention. However, a follow-up analysis reveals that scores correlate almost perfectly with reading fluency but show little relationship with tasks that require logical reasoning or argument evaluation. The test is actually measuring reading speed and decoding ability — not critical thinking. This is a construct validity failure: the operationalization does not match the theoretical construct.
Example 2 — Measuring “intrinsic motivation” or social desirability?
A researcher develops a self-report questionnaire to measure students’ intrinsic motivation for learning. Items include: “I study because I genuinely enjoy learning new things.” Students who want to appear to be good students may give socially desirable answers regardless of their true feelings. If the scale correlates strongly with a social desirability scale but weakly with actual time-on-task or voluntary reading behavior, the instrument may be capturing social desirability rather than intrinsic motivation itself.
Example 3 — Convergent and discriminant validity of a “self-efficacy” scale
A psychologist creates a new academic self-efficacy scale for college students. To validate it:
- Convergent validity check: The scale should correlate strongly with other established self-efficacy measures (e.g., Bandura’s Self-Efficacy Scale) and with related constructs like academic confidence. ✓
- Discriminant validity check: The scale should not correlate highly with conceptually unrelated constructs like extraversion or physical self-esteem. If it does, the scale may be measuring something broader than academic self-efficacy. ✗
Both checks together provide evidence that the instrument measures what it claims to measure.
Example 4 — Mono-method bias in measuring student well-being
A researcher assesses student psychological well-being using only a single self-report survey administered once at the end of the semester. Because students are tired and may under-report positive emotions at that time of year, the measure under-represents the true construct. Using multiple methods — self-report, teacher ratings, behavioral observation, and physiological measures — across multiple time points would yield a more construct-valid picture of well-being.
2.8.1 Construct Validity II
- Threats:
- Experimenter bias: The experimenter transfers expectations to the participants in a manner that affects performance on dependent variables.
- For instance, the researcher might look pleased when participants give a desired answer.
- If this is what causes the response, it would be wrong to label the response as a treatment effect.
- Condition diffusion: The possibility of communication between participants from different condition groups during the evaluation.
- Resentful demoralization: A group that is receiving nothing (control/placebo) finds out that a condition (treatment) that others are receiving is effective.
- Inadequate Preoperational Explication: Preoperational means before translating constructs into measures or treatments, and explication means explanation.
- The researcher did not do a good enough job of defining (operationally) what was meant by the construct.
- Mono-method bias: The use of only a single dependent variable to assess a construct may result in under-representing the construct and containing irrelevancies.
- Mono-operation bias: The use of only a single implementation of the independent variable, program, or treatment in a study.
- Experimenter bias: The experimenter transfers expectations to the participants in a manner that affects performance on dependent variables.
2.8.2 Construct Validity III
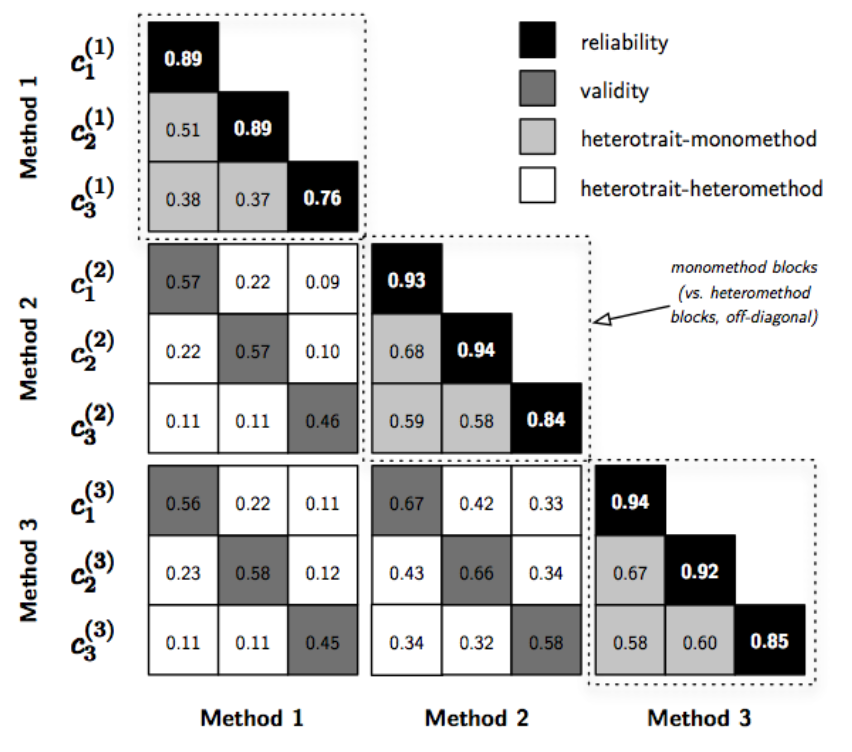
- Multitrait-Multimethod Matrix (MTMM):
- The MTMM is an approach to assessing the construct validity of a set of measures in a study (Campbell & Fiske, 1959).
- Along with the MTMM, Campbell and Fiske introduced two new types of validity, both of which the MTMM assesses:
- Convergent validity: the degree to which concepts that should be related theoretically are interrelated in reality.
- Discriminant validity: the degree to which concepts that should NOT be related theoretically are, in fact, not interrelated in reality.
- In order to claim that your measures have construct validity, you must demonstrate both convergence and discrimination.
2.8.3 Construct Validity IV
- Multitrait-Multimethod Matrix (MTMM):
- Example: Three traits to be measured: c1 (geometry), c2 (algebra), and c3 (reasoning).
- Each trait was measured by three methods.
- e.g., notation: c_3^{(2)} is trait 3 measured by method 2.
- Coefficients in the reliability diagonal should consistently be the highest in the matrix: a trait should be more highly correlated with itself than with anything else!
- Coefficients in the validity diagonals should be significantly different from zero and high enough to warrant further investigation.
- This is essentially used as evidence of convergent validity.
2.10 Wrap-up
- Choosing the Right Design: The selection of an experimental design — from a simple post-test to a complex factorial or repeated measures design — is crucial for effectively answering your research question. Each design has unique strengths for controlling different variables and threats.
- The Four Pillars of Validity: A well-designed experiment is not enough; its conclusions must be valid. Always consider the four key types of validity to ensure your findings are trustworthy:
- Statistical Validity: Are your statistical conclusions accurate?
- Internal Validity: Did your treatment truly cause the effect?
- Construct Validity: Are you measuring what you intend to measure?
- External Validity: Can your findings be generalized to other people, settings, and times?